Все курсы > Вводный курс > Занятие 19
Сегодня мы рассмотрим тему обработки естественного языка (Natural Language Processing, NLP), области на стыке математики, информатики и лингвистики, занимающейся пониманием (анализом) и созданием (синтезом) текстов с помощью компьютера.
В частности мы разберем тему (1) предварительной обработки языка (language pre-processing), (2) а также изучим два несложных способа анализа содержания текста (topic identification).
Постановка задачи
В школьных учебниках можно встретить такое задание: «Прочитайте текст. Определите его тему». У человека, как правило, это не вызывает никаких сложностей. Теперь представьте, что вы компьютер. Как понять, о чем говорится в тексте?
В качестве примера, возьмем следующий текст на английском языке:
When we were in Paris we visited a lot of museums. We first went to the Louvre, the largest art museum in the world. I have always been interested in art so I spent many hours there. The museum is enourmous, so a week there would not be enough.
Если вы попросите меня описать содержание тремя или четырьмя словами, я бы сказал: «музей» (museum), «Лувр» (Louvre), «Париж» (Paris), «искусство» (art). Посмотрим, что скажет компьютер.
По традиции вначале откроем ноутбук к этому занятию⧉
|
1 2 |
# возьмём исходный текст для анализа corpus = 'When we were in Paris we visited a lot of museums. We first went to the Louvre, the largest art museum in the world. I have always been interested in art so I spent many hours there. The museum is enourmous, so a week there would not be enough.' |
В лингвистике совокупность рассматриваемых текстов принято называть корпусом (corpus, мн.ч. кóрпусы, corpora).
Импортируем пакет библиотек для обработки естественного языка (Natural Language Toolkit или NLTK) и другие уже известные нам библиотеки.
|
1 2 3 |
import nltk import pandas as pd import numpy as np |
Предварительная обработка текста
Шаг 1. Разделение на предложения
Вначале текст логично разделить на предложения или токенизировать. Хотя задача кажется тривиальной (достаточно разделить текст по точкам, восклицательным и вопросительным знакам), есть несколько сложностей. Например, фраза «Мороженое стоит 100 руб. 20 коп.» может быть ошибочно разбита на два предложения. Помимо сокращений есть и другие сложности. Например, из-за опечатки предложение может заканчиваться пробелом, а не знаком препинания.
Для решения этой задачи можно использовать стандартный метод библиотеки NLTK sent_tokenize.
|
1 2 3 4 5 6 7 8 9 |
# импортируем метод sent_tokenize from nltk.tokenize import sent_tokenize # скачиваем модель, которая будет делить на предложения nltk.download('punkt') # и применяем метод к нашему тексту sentences = sent_tokenize(corpus) sentences |
|
1 2 3 4 |
['When we were in Paris we visited a lot of museums.', 'We first went to the Louvre, the largest art museum in the world.', 'I have always been interested in art so I spent many hours there.', 'The museum is enourmous, so a week there would not be enough.'] |
Метод использует уже обученную модель, в нашем случае, для английского языка: nltk_data/tokenizers/punkt/english.pickle. Также можно использовать модели для других языков или обучить собственную модель.
Шаг 2. Разделение на слова
Разделение на слова или токенизация слов — следующий шаг в обработке текста. В целом используется аналогичный подход и метод word_tokenize. Для примера, разобьем на слова первое предложение.
|
1 2 3 4 5 |
# импортируем метод word_tokenize from nltk.tokenize import word_tokenize # и разобьём на слова первое предложение print(word_tokenize(sentences[0])) |
|
1 |
['When', 'we', 'were', 'in', 'Paris', 'we', 'visited', 'a', 'lot', 'of', 'museums', '.'] |
Сделаем то же самое для всего текста.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# для этого создадим пустой список tokens = [] # в цикле for пройдемся по каждому предложению for sentence in sentences: # создадим списки из токенов t = word_tokenize(sentence) # и присоединим списки друг к другу tokens.extend(t) print(tokens) |
|
1 |
['When', 'we', 'were', 'in', 'Paris', 'we', 'visited', 'a', 'lot', 'of', 'museums', '.', 'We', 'first', 'went', 'to', 'the', 'Louvre', ',', 'the', 'largest', 'art', 'museum', 'in', 'the', 'world', '.', 'I', 'have', 'always', 'been', 'interested', 'in', 'art', 'so', 'I', 'spent', 'many', 'hours', 'there', '.', 'The', 'museum', 'is', 'enourmous', ',', 'so', 'a', 'week', 'there', 'would', 'not', 'be', 'enough', '.'] |
Шаг 3. Перевод в нижний регистр, удаление стоп-слов и знаков пунктуации
Выясняется, что для анализа текста далеко не все слова являются релевантными. Если мы попробуем применить к тексту статистические методы, то многие важные с точки зрения человеческой грамматики слова будут нам только мешать. В частности, это предлоги, союзы и артикли. Назовем их «стоп-словами» и попробуем опустить.
Перед этим обязательно преобразуем все заглавные буквы в строчные.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# импортируем модуль стоп-слов from nltk.corpus import stopwords # скачаем словарь стоп-слов nltk.download('stopwords') # мы используем set, чтобы оставить только уникальные значения unique_stops = set(stopwords.words('english')) # создаём пустой список без стоп-слов no_stops = [] # проходимся по всем токенам for token in tokens: # переводим все слова в нижний регистр token = token.lower() # если токен не в списке стоп-слов и не является знаком пунктуации if token not in unique_stops and token.isalpha(): # добавляем его в список no_stops.append(token) print(no_stops) |
|
1 |
['paris', 'visited', 'lot', 'museums', 'first', 'went', 'louvre', 'largest', 'art', 'museum', 'world', 'always', 'interested', 'art', 'spent', 'many', 'hours', 'museum', 'enourmous', 'week', 'would', 'enough'] |
Как вы вероятно заметили, мы дополнительно удалили пунктуацию с помощью метода isalpha().
Шаг 4. Лемматизация
Кроме того, с точки зрения анализа содержания слова «музеи» и «музей» означают одно и то же, но компьютер посчитает их разными словами. Значит, слова нужно привести к начальной (словарной) форме или лемме.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# импортируем класс для лемматизации from nltk.stem import WordNetLemmatizer # импортируем словарь nltk.download('wordnet') # создаём объект этого класса lemmatizer = WordNetLemmatizer() # и пустой список для слов после лемматизации lemmatized = [] # проходимся по всем токенам for token in no_stops: # применяем лемматизацию token = lemmatizer.lemmatize(token) # добавляем слово после лемматизации в список lemmatized.append(token) print(lemmatized) |
|
1 |
['paris', 'visited', 'lot', 'museum', 'first', 'went', 'louvre', 'largest', 'art', 'museum', 'world', 'always', 'interested', 'art', 'spent', 'many', 'hour', 'museum', 'enourmous', 'week', 'would', 'enough'] |
WordNet Lemmatizer библиотеки NLTK использует базу данных WordNet⧉ для поиска словарной формы слова.
Шаг 5. Стемминг
Стемминг (stemming), в отличие от лемматизации, ориентирован на поиск основы слова (stem). Попробуем применить и его.
Для начала используем стеммер (т.е. инструмент стемминга) Портера. Он достаточно консервативен, т.е. не так активно обрезает слова в поисках основы.
|
1 2 3 4 5 6 7 8 |
# импортируем класс стеммера Porter и создаём объект этого класса from nltk.stem import PorterStemmer porter = PorterStemmer() # используем list comprehension вместо цикла for для стемминга и создания нового списка # такая запись намного короче stemmed_p = [porter.stem(s) for s in lemmatized] print(stemmed_p) |
|
1 |
['pari', 'visit', 'lot', 'museum', 'first', 'went', 'louvr', 'largest', 'art', 'museum', 'world', 'alway', 'interest', 'art', 'spent', 'mani', 'hour', 'museum', 'enourm', 'week', 'would', 'enough'] |
Как вы видите, list comprehension позволяет в одну строчку создавать список. Подробнее этот прием мы рассмотрим на следующем курсе.
Теперь применим более агрессивный стеммер Ланкастера.
|
1 2 3 4 5 6 7 |
# аналогично импортируем класс Lancaster и создаём объект этого класса from nltk.stem import LancasterStemmer lancaster = LancasterStemmer() # также используем list_comprehension stemmed_l = [lancaster.stem(s) for s in lemmatized] print(stemmed_l) |
|
1 |
['par', 'visit', 'lot', 'muse', 'first', 'went', 'louvr', 'largest', 'art', 'muse', 'world', 'alway', 'interest', 'art', 'spent', 'many', 'hour', 'muse', 'enourm', 'week', 'would', 'enough'] |
К сожалению, ни тот, ни другой не показали хороших результатов. Стемминг к нашему тексту мы применять не будем.
Мешок слов
Принцип метода мешка слов (Bag of Words, BoW) чрезвычайно прост. Мы считаем как часто встречается каждое слово в тексте.
Несмотря на простоту, при правильной предобработке текста (в первую очередь удалении стоп-слов, которые и будут наиболее частотными) этот метод показывает неплохие результаты. Применим его к нашему тексту с помощью класса Counter модуля Collections.
|
1 2 3 4 5 6 7 8 9 10 11 |
# из модуля collections импортируем класс Counter from collections import Counter # применяем класс Counter к словам после лемматизации # на выходе нам возвращается словарь { слово : его частота в тексте } bow_counter = Counter(lemmatized) # print(bow_counter) # функция most_common() упорядочивает словарь по значению # посмотрим на первые 10 наиболее частотных слов print(bow_counter.most_common(10)) |
|
1 |
[('museum', 3), ('art', 2), ('paris', 1), ('visited', 1), ('lot', 1), ('first', 1), ('went', 1), ('louvre', 1), ('largest', 1), ('world', 1)] |
Этот же метод можно реализовать с помощью класса CountVectorizer библиотеки Scikit-learn.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# импортируем класс CountVectorizer из библиотеки Scikit-learn from sklearn.feature_extraction.text import CountVectorizer # создаём объект этого класса и # указываем, что хотим перевести слова в нижний регистр, а также # отфильтровать стоп-слова через stop_words = 'english' vectorizer = CountVectorizer(analyzer = "word", lowercase = True, tokenizer = None, preprocessor = None, stop_words = 'english', max_features = 5000) |
|
1 2 3 4 5 |
# применяем этот объект к предложениям (ещё говорят документам) bow_cv = vectorizer.fit_transform(sentences) # на выходе получается матрица csr print(type(bow_cv)) |
|
1 |
<class 'scipy.sparse.csr.csr_matrix'> |
Преобразуем матрицу csr в привычный формат массива Numpy.
|
1 2 |
# для этого можно использовать .toarray() print(bow_cv.toarray()) |
|
1 2 3 4 |
[[0 0 0 0 0 1 0 0 1 1 0 1 0 0 0] [1 0 0 0 1 0 1 1 0 0 0 0 0 1 1] [1 0 1 1 0 0 0 0 0 0 1 0 0 0 0] [0 1 0 0 0 0 0 1 0 0 0 0 1 0 0]] |
Строки предсталяют собой предложения (документы), столбцы — слова (токены).
|
1 |
bow_cv.shape |
|
1 |
(4, 15) |
Есть два способа посмотреть на используемые токены. С помощью атрибута vocabulary_.
|
1 2 3 |
# здесь числа это не частотность, а просто порядковый номер (индекс) vocab = vectorizer.vocabulary_ print(vocab) |
|
1 |
{'paris': 9, 'visited': 11, 'lot': 5, 'museums': 8, 'went': 13, 'louvre': 6, 'largest': 4, 'art': 0, 'museum': 7, 'world': 14, 'interested': 3, 'spent': 10, 'hours': 2, 'enourmous': 1, 'week': 12} |
Здесь числа это не частотность слов, а просто их порядковый номер или индекс. Также токены можно вывести с помощью метода .get_feature_names_out().
|
1 |
tokens = vectorizer.get_feature_names_out() |
|
1 2 |
['art' 'enourmous' 'hours' 'interested' 'largest' 'lot' 'louvre' 'museum' 'museums' 'paris' 'spent' 'visited' 'week' 'went' 'world'] |
Результат для удобства также можно преобразовать в датафрейм.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# вначале создадим индекс предложений (документов) index_list = [] # в цикле пройдемся по элементам матрицы, обозначим их через '_' # функция enumerate задаст каждому элементу индекс, начиная с 0 for i, _ in enumerate(bow_cv): # прибавим наш индекс к слову Sentence index_list.append(f'Sentence_{i}') # теперь можно использовать pd.DataFrame bow_cv_df = pd.DataFrame(data = bow_cv.toarray(), index = index_list, columns = tokens) bow_cv_df |

Итог работы CountVectorizer может показаться менее наглядным, чем метод мешка слов (и кроме того у него нет встроенной возможности лемматизации и стемминга), однако этот класс позволяет выразить слова с помощью числовых векторов.
Это очень важный результат, о котором мы поговорим в конце занятия.
Метод TF-IDF
Чуть более сложный и продвинутый метод определения значимости слов в тексте называется TF-IDF (term frequency — inverse document frequency).
Основная идея
Если слово часто встречается во всех документах (это в первую очередь касается предлогов, союзов и других стоп-слов), то вряд ли эти слова имеют большое значение. И наоборот, если слово встречаться только в одном документе, вероятно оно в большей степени определяет его содержание.
Другими словами, определяется не только значимость слова в тексте, но и значимость слова с учётом всех текстов.
Простой пример и формула
Предположим, что у нас есть два текста и мы посчитали частотность слов в каждом из них (т.е. создали мешок слов).
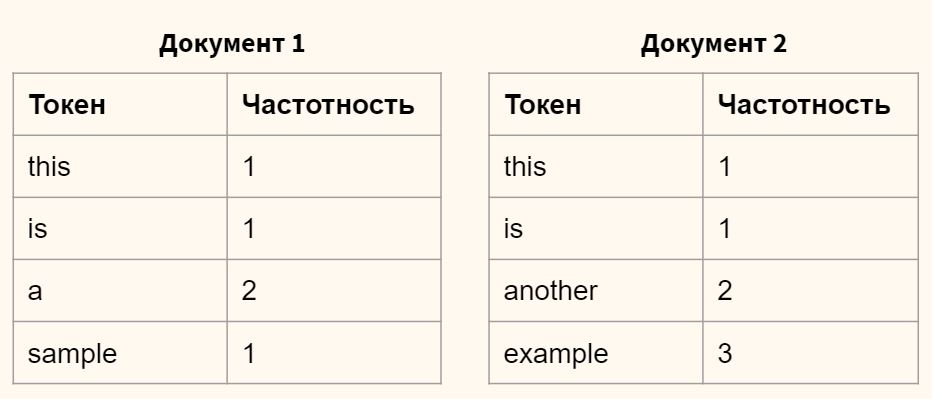
Расчет tf-idf для слова this
Поставим себе задачу рассчитать TF-IDF для слова this в каждом из документов. На первом этапе вычисляем частоту слова (term frequency или TF) относительно всех слов в документе.
$$ tf(this, d_1) = \frac{частотность \space слова}{всего \space слов} = \frac{1}{5} = 0.2 $$
$$ tf(this, d_2) = \frac{частотность \space слова}{всего \space слов} = \frac{1}{7} \approx 0.14 $$
Такой подход гарантирует, что мы учитываем как часто встречается слово относительно длины документа.
На втором этапе рассчитаем IDF слова this. То есть мы делим общее количество документов в корпусе на количество документов, в которых встречается искомый токен, и берем логарифм (в данном случае, десятичный) частного.
$$ idf(this, D) = \log_{10} \left(\frac{всего\spaceдокументов}{документов\spaceс\spaceтокеном}\right) = \log_{10} \left( \frac{2}{2} \right) = 0 $$
Остаётся перемножить TF и IDF.
$$ tf-idf (this, d_1, D) = 0.2 \times 0 = 0 $$
$$ tf-idf (this, d_2, D) = 0.14 \times 0 = 0 $$
Этот показатель равен нулю, что отражает низкую значимость слова this для обоих документов. Теперь сделаем аналогичный расчет для слова example.
Расчет tf-idf для слова example
$$ tf(example, d_1) = \frac{0}{5} = 0 $$
$$ tf(example, d_2) = \frac{3}{7} \approx 0.429 $$
$$ idf(example, D) = \log_{10} \left( \frac{2}{1} \right) \approx 0.301 $$
$$ tf-idf (example, d_1, D) = 0 \times 0.301 = 0 $$
$$ tf-idf (example, d_2, D) = 0.429 \times 0.301 \approx 0.129 $$
В данном случае слово example имеет заметно большее значение для второго документа. Для первого документа его значимость по-прежнему равна нулю (такого слова там нет).
Логика формулы следующая, чем выше частота слова в документе (tf) и чем реже оно встречается в целом в документах (idf), тем выше общий показатель (tf-idf).
Также замечу, что на практике эти формулы часто модифицируют. Например, к знаменателю формулы расчета idf добавляют единицу, чтобы избежать деления на ноль, если документов с таким токеном не нашлось.
$$ idf = \log \left(\frac{всего\spaceдокументов}{документов\spaceс\spaceтокеном + 1}\right) $$
TF-IDF с помощью библиотеки Scikit-learn
Применим этот метод к нашему исходному тексту про Париж и музеи. Вначале последовательно используем классы CountVectorizer и TfidfTransformer.
Способ 1. CountVectorizer + TfidfTransformer
TF или частоту слов мы можем взять из предыдущего раздела.
|
1 |
bow_cv |
|
1 2 |
<4x15 sparse matrix of type '<class 'numpy.int64'>' with 17 stored elements in Compressed Sparse Row format> |
Теперь нужно рассчитать IDF.
|
1 2 3 4 5 6 7 8 9 10 11 |
# импортируем TfidfTransformer (CountVectorizer уже импортирован) from sklearn.feature_extraction.text import TfidfTransformer # создадим объект класса TfidfTransformer tfidf_trans = TfidfTransformer(smooth_idf = True, use_idf = True) # и рассчитаем IDF слов tfidf_trans.fit(bow_cv) # поместим результат в датафрейм df_idf = pd.DataFrame(tfidf_trans.idf_, index = tokens, columns = ["idf_weights"]) |
Остается TF x IDF.
|
1 2 3 |
# рассчитаем TF-IDF (по сути умножим TF на IDF) tf_idf_vector = tfidf_trans.transform(bow_cv) tf_idf_vector |
|
1 2 |
<4x15 sparse matrix of type '<class 'numpy.float64'>' with 17 stored elements in Compressed Sparse Row format> |
Теперь мы можем посмотреть на показатель TF-IDF для конкретного слова в конкретном документе.
|
1 2 3 4 5 |
# для этого переведем матрицу csr в обычный массив Numpy df_tfidf = pd.DataFrame(tf_idf_vector.toarray(), columns = vectorizer.get_feature_names_out()) # и траспонируем его (запишем столбцы в виде строк) print(df_tfidf.T) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
0 1 2 3 art 0.0 0.344315 0.414289 0.000000 enourmous 0.0 0.000000 0.000000 0.617614 hours 0.0 0.000000 0.525473 0.000000 interested 0.0 0.000000 0.525473 0.000000 largest 0.0 0.436719 0.000000 0.000000 lot 0.5 0.000000 0.000000 0.000000 louvre 0.0 0.436719 0.000000 0.000000 museum 0.0 0.344315 0.000000 0.486934 museums 0.5 0.000000 0.000000 0.000000 paris 0.5 0.000000 0.000000 0.000000 spent 0.0 0.000000 0.525473 0.000000 visited 0.5 0.000000 0.000000 0.000000 week 0.0 0.000000 0.000000 0.617614 went 0.0 0.436719 0.000000 0.000000 world 0.0 0.436719 0.000000 0.000000 |
Всего после обработки метод оставил 15 слов.
|
1 |
df_tfidf.T.shape |
|
1 |
(15, 4) |
Такого же результата можно добиться применив метод Tfidfvectorizer.
Способ 2. Tfidfvectorizer
|
1 2 3 4 5 6 7 8 |
# импортируем класс TfidfVectorizer from sklearn.feature_extraction.text import TfidfVectorizer # создаем объект класса TfidfVectorizer tfIdfVectorizer = TfidfVectorizer(use_idf = True, stop_words= 'english') # сразу рассчитываем TF-IDF слов tfIdf = tfIdfVectorizer.fit_transform(sentences) |
Мы можем посмотреть какие слова остались после фильтрации.
|
1 |
print(tfIdfVectorizer.get_feature_names_out()) |
|
1 2 |
['art' 'enourmous' 'hours' 'interested' 'largest' 'lot' 'louvre' 'museum' 'museums' 'paris' 'spent' 'visited' 'week' 'went' 'world'] |
В частности мы видим, что метод Tfidfvectorizer оставил теже слова, что и CountVectorizer и TfidfTransformer. Посмотрим IDF слов.
|
1 |
tfIdfVectorizer.idf_ |
|
1 2 3 |
array([1.51082562, 1.91629073, 1.91629073, 1.91629073, 1.91629073, 1.91629073, 1.91629073, 1.51082562, 1.91629073, 1.91629073, 1.91629073, 1.91629073, 1.91629073, 1.91629073, 1.91629073]) |
Посмотрим на количество документов и количество токенов (слов).
|
1 |
tfIdf.shape |
|
1 |
(4, 15) |
Рассчитаем значение TF-IDF для каждого слова по каждому тексту.
|
1 2 3 4 |
# посмотрим на значение TF-IDF для конкретного слова в конкретном документе # чем оно уникальнее для конкретного документа, тем выше показатель df_tfidf = pd.DataFrame(tfIdf.toarray(), columns = tfIdfVectorizer.get_feature_names_out()) print(df_tfidf.T) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
0 1 2 3 art 0.0 0.344315 0.414289 0.000000 enourmous 0.0 0.000000 0.000000 0.617614 hours 0.0 0.000000 0.525473 0.000000 interested 0.0 0.000000 0.525473 0.000000 largest 0.0 0.436719 0.000000 0.000000 lot 0.5 0.000000 0.000000 0.000000 louvre 0.0 0.436719 0.000000 0.000000 museum 0.0 0.344315 0.000000 0.486934 museums 0.5 0.000000 0.000000 0.000000 paris 0.5 0.000000 0.000000 0.000000 spent 0.0 0.000000 0.525473 0.000000 visited 0.5 0.000000 0.000000 0.000000 week 0.0 0.000000 0.000000 0.617614 went 0.0 0.436719 0.000000 0.000000 world 0.0 0.436719 0.000000 0.000000 |
В целом упражнение можно завершить. Однако напомню, что нашей целью было определить тему текста. Для этого мы также можем рассчитать среднее значение TF-IDF для каждого слова по всем текстам.
Вычислим среднее арифметическое по строкам матрицы, приведенной выше (подробное объяснение кода вы найдете в ноутбуке⧉).
|
1 2 |
mean_weights = np.asarray(tfIdf.mean(axis = 0)).ravel().tolist() mean_weights |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
[0.18965081782108964, 0.15440359274390048, 0.13136818731601646, 0.13136818731601646, 0.10917982746877804, 0.125, 0.10917982746877804, 0.2078121960479979, 0.125, 0.125, 0.13136818731601646, 0.125, 0.15440359274390048, 0.10917982746877804, 0.10917982746877804] |
И создадим датафрейм, отсортировав слова по убыванию средних весов.
|
1 2 3 4 5 |
# создаём датафрейм из словаря mean_weights_df = pd.DataFrame({'term': tfIdfVectorizer.get_feature_names_out(), 'mean_weights': mean_weights}) # сортируем по убыванию 10 слов с максимальным средним TF-IDF mean_weights_df.sort_values(by = 'mean_weights', ascending = False).reset_index(drop = True).head(10) |

Результаты
Как мы видим, ни один из алгоритмов не справился со своей задачей на отлично. Отчасти это связано с ограничениями самих методов, отчасти с тем, что мы взяли очень небольшой текст для анализа.
При этом несмотря на неидеальный результат, мы добились, как уже было сказано, векторизации текста, то есть описания его с помощью чисел.

Дополнительные примеры
Прежде чем завершить, я покажу два примера применения текстовых векторов.
Косинусное расстояние между текстовыми векторами
Возьмем два предложения и объединим их в корпус.
|
1 2 3 4 |
text1 = 'all the world’s a stage, and all the men and women merely players' text2 = 'you must be the change you wish to see in the world' corpus = [text1, text2] |
Создадим объект класса TfidfVectorizer и рассчитаем веса tf-idf.
|
1 2 3 4 5 6 7 8 |
# создадим объект класса TfidfVectorizer tfIdfVectorizer = TfidfVectorizer(use_idf = True, stop_words = 'english') # на выходе получаем два вектора, где каждое значение - это вес (показатель tf-idf) слова X = tfIdfVectorizer.fit_transform(corpus) # преобразуем данные формат массива Numpy print(X.toarray()) |
|
1 2 3 4 |
[[0. 0.4261596 0.4261596 0.4261596 0.4261596 0. 0.4261596 0.30321606] [0.6316672 0. 0. 0. 0. 0.6316672 0. 0.44943642]] |
Для удобства, мы можем преобразовать данные в датафрейм.
|
1 2 3 4 5 |
# данными станут веса ti-idf, индексом - список векторов, столбцами - токены vectors_df = pd.DataFrame(data = X.toarray(), index = ['vector1', 'vector2'], columns = tfIdfVectorizer.get_feature_names_out()) vectors_df |

Вектора готовы. Напомню формулу расчета косинусного расстояния.
$$ \cos \theta ={\mathbf {a} \cdot \mathbf {b} \over \|\mathbf {a} \|\|\mathbf {b} \|} $$
Теперь поместим каждый вектор в отдельную переменную.
|
1 2 |
vector1 = X.toarray()[0] vector2 = X.toarray()[1] |
Выполним операции в числителе формулы.
|
1 2 |
# рассчитаем скалярное произведение векторов numerator = np.dot(vector1, vector2) |
Займемся знаменателем.
|
1 2 3 4 5 6 |
# (1) рассчитаем длины (по большому счету, это теорема Пифагора) vector1Len = np.linalg.norm(vector1) vector2Len = np.linalg.norm(vector2) # (2) перемножим их denominator = vector1Len * vector2Len |
Остается рассчитать косинус угла.
|
1 2 3 |
# посмотрим, чему равен косинус угла между векторами cosine = numerator/denominator cosine |
|
1 |
0.13627634143908643 |
И после этого перевести его в радианы, а затем в градусы.
|
1 2 3 4 5 6 7 |
# найдем угол в градусах по его косинусу # для этого вначале вычислим угол в радианах angle_radians = np.arccos(cosine) # затем в градусах angle_degrees = angle_radians * 360/2/np.pi round(angle_degrees, 2) |
|
1 |
82.17 |
Кластерный анализ текста
Теперь давайте посмотрим, как можно разделить предложения в тексте на темы (кластеры). Возьмем текст с предложениями из Википедии, посвященных науке о данных и Большому театру.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
text = ''' Data science is an interdisciplinary field that uses scientific methods, processes, algorithms and systems to extract knowledge and insights from noisy, structured and unstructured data. It applies knowledge and actionable insights from data across a broad range of application domains. Data science is related to data mining, machine learning and big data. The Bolshoi Theatre is a historic theatre in Moscow, Russia. It was originally designed by architect Joseph Bové, which holds ballet and opera performances. Before the October Revolution it was a part of the Imperial Theatres of the Russian Empire along with Maly Theatre in Moscow and a few theatres in Saint Petersburg. Data science is a concept to unify statistics, data analysis, informatics, and their related methods in order to understand and analyze actual phenomena with data. However, data science is different from computer science and information science. The main building of the theatre, rebuilt and renovated several times during its history, is a landmark of Moscow and Russia. On 28 October 2011, the Bolshoi re-opened after an extensive six-year renovation. ''' |
Разобьем текст на преложения и переведем в нижний регистр.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# создадим список из предложений corpus = [] # для этого в цикле for пройдемся по тексту, разделив его по символу новой строки \n for line in text.split('\n'): # если строка не пустая (т.е. True) if line: # переводим ее в нижний регистр line = line.lower() # и добавляем в список corpus.append(line) corpus |
|
1 2 3 4 5 6 7 8 9 10 |
['data science is an interdisciplinary field that uses scientific methods, processes, algorithms and systems to extract knowledge and insights from noisy, structured and unstructured data.', 'it applies knowledge and actionable insights from data across a broad range of application domains.', 'data science is related to data mining, machine learning and big data.', 'the bolshoi theatre is a historic theatre in moscow, russia.', 'it was originally designed by architect joseph bové, which holds ballet and opera performances.', 'before the october revolution it was a part of the imperial theatres of the russian empire along with maly theatre in moscow and a few theatres in saint petersburg.', 'data science is a concept to unify statistics, data analysis, informatics, and their related methods in order to understand and analyze actual phenomena with data.', 'however, data science is different from computer science and information science.', 'the main building of the theatre, rebuilt and renovated several times during its history, is a landmark of moscow and russia.', 'on 28 october 2011, the bolshoi re-opened after an extensive six-year renovation.'] |
Создадим векторы каждого из предложений.
|
1 2 3 4 5 |
# применим TfidfVectorizer tfIdfVectorizer = TfidfVectorizer(use_idf = True, stop_words= 'english') # на выходе получаем векторы предложений X = tfIdfVectorizer.fit_transform(corpus) |
Применим алгоритм k-средних и разделим предложения на кластеры.
|
1 2 3 4 5 |
# импортируем алгоритм k-средних из библиотеки sklearn from sklearn.cluster import KMeans # так как мы знаем, что темы две, используем гиперпараметр k = 2 kmeans = KMeans(n_clusters = 2, n_init = 10, random_state = 42).fit(X) |
Как результат, мы создали две модели:
- Модель векторизации через tfIdfVectorizer
- Модель кластеризации
Возьмем новые предложения и с помощью обученных моделей разобьем их на кластеры.
|
1 2 3 4 5 6 7 8 |
# возьмем новые предложения, первое из области Data Science и два других про Большой театр prediction = ['Many statisticians, including Nate Silver, have argued that data science is not a new field, but rather another name for statistics.', 'Urusov set up the theatre in collaboration with English tightrope walker Michael Maddox.', 'Until the mid-1990s, most foreign operas were sung in Russian, but Italian and other languages have been heard more frequently on the Bolshoi stage in recent years.'] # применим две модели, сначала создадим векторы новых предложений (tfIdfVectorizer.transform), # затем отнесем их к одному из кластеров (kmeans.predict) kmeans.predict(tfIdfVectorizer.transform(prediction)) |
|
1 |
array([0, 1, 1], dtype=int32) |
Как мы видим, первое предложение отнесено к одному кластеру, второе и третье — к другому.
Подведем итог
Сегодня мы впервые поработали с текстами. В частности, научились предварительно обрабатывать их и анализировать содержание. Для этого мы использовали метод мешка слов и метод TF-IDF. Второй метод позволил превратить предложения в числа или векторизовать их.
Благодаря векторизации предложений, мы смогли рассчитать косинусное сходство между двумя документами и провести кластерный анализ текста.
Вопросы для закрепления
Перечислите способы предварительной обработки текста
Посмотреть правильный ответ
Ответ: (1) разделение на предложения, (2) разделение на слова, (3) перевод в нижний регистр, удаление стоп-слов и знаков препинания, (4) лемматизация (приведение к начальной форме) и (5) стемминг (выявление основы)
В чем отличие мешка слов от метода TF-IDF?
Посмотреть правильный ответ
Ответ: (1) мешок слов предполагает простой подсчет частоты конкретного слова в тексте, (2) метод TF-IDF учитывает как значимость слова в одном документе, так и частоту этого слова во всех документах корпуса (чем эта частота ниже, тем выше значимость слова)
Что позволяет нам выполнять математические операции над текстом?
Посмотреть правильный ответ
Ответ: преобразование в векторы (векторизация)
На следующем занятии мы поговорим про анализ временных рядов.
Ответы на вопросы
Вопрос. Имеет ли значение какое основание логарифма использовать в формуле TF-IDF?
Ответ. Нет, не имеет, основание может быть любым. В формуле выше используется десятичный логарифм, sklearn использует натуральный.
Вопрос. Во втором дополнительном примере, откуда мы знаем, что кластеров должно быть два (в алгоритме k-means)?
Ответ. В данном случае, мы либо заранее знаем, что темы две, и нам нужно научить алгоритм разделять тексты на эти два кластера, либо попробовать метод локтя, как мы это делали на занятии по кластеризации.
Вопрос. Зачем мы применили .ravel() к массиву при работе с TfidfVectorizer (способ 2)? То есть зачем убирали второе измерение?
Ответ. Мы это сделали, чтобы затем корректно сработала функция tolist(). Если не использовать .ravel(), то применив только tolist() мы получим вложенные списки [[some_list]], а нам нужен обычный список [some_list].
Попробуйте в качестве эксперимента обойтись без .ravel().