Все курсы > Программирование на Питоне > Занятие 13
Сегодня мы изучим в целом, как можно создать программу на Питоне.
Способ 1. Писать код в облаке в Google Colab.
Способ 2. Написать программу в отдельном файле (скрипте) с расширением .py и передать этот код специальному интерпретатору для исполнения.
Способ 3. Установить Jupyter Notebook (локальный аналог Google Colab).
С первым способом мы уже познакомились в рамках вводного курса. Сегодня мы займемся написанием программы в отдельном файле, а в следующий раз — изучим Jupyter Notebook.
Кроме того, мы рассмотрим возможности по созданию собственных модулей и пакетов в Питоне.
Установка Питона на Windows
Прежде чем мы начнем писать программу, нам нужно установить библиотеки (libraries) и интерпретатор (interpreter) для обработки кода.
Шаг 1. Проверить, установлен ли Питон на вашем компьютере
Для этого вначале нажмите клавишу Windows и клавишу R на клавиатуре.

В появившемся окне «Выполнить» введите cmd и нажмите Enter.

Появится так называемая «командная строка» (Command Line Promt) — отдельная программа, позволяющая взаимодействовать с Windows не графически (как мы привыкли это делать), а через текстовые команды.

Теперь введите python --version. Если Питон установлен, то программа сообщит текущую версию. В противном случае появится вот такая запись.

Если Питон не установлен, переходите к шагу 2. В случае если вы его уже установили, переходите сразу к шагу 3.
Шаг 2. Скачать Питон с официального сайта
Перейдем на сайт www.python.org/dowloads/⧉ и скачаем, среди прочего, базовый функционал Питона, а также интерпретатор для Windows, который позволит нам исполнять написанный нами код.
После скачивания и запуска файла откроется мастер установки.

Нижняя галочка добавит Питон в переменную окружения PATH. Благодаря этому мы сможем исполнять код на Питоне напрямую из командной строки. Мы разберем как это делается уже на следующем шаге.
Снова проверим установку Питона на компьютере, повторив действия Шага 1. В командной строке должна появиться установленная на данный момент версия Питона.

Шаг 3. Запустить Питон из командной строки
Теперь давайте введем в командной строке команду py. Должны появиться символы >>>.

Это значит, что командная строка перешла в интерактивный режим, и мы можем писать код на Питоне.
Напишем классическую фразу:
|
1 |
print('Hello World!') |
При корректном исполнении кода фраза будет выведена на экран.

Однако, как вы помните, наша задача — исполнить не отдельную команду, а скрипт, то есть целую программу на Питоне, а для этого нам нужно эту программу создать.
Поэтому выйдем из интерактивного режима с помощью команды quit() или exit(), закроем окно командной строки и перейдем к созданию программы на Питоне.
Создание программы на Питоне
Технически для создания программы нам понадобится редактор кода. В нем мы будем создавать файлы с расширением .py и передавать их интерпретатору.
Шаг 1. Скачать редактор кода
Редактор кода — это текстовый редактор, который, среди прочего, правильно подсвечивает код на том языке, на котором вы программируете.
В принципе, если вы работаете на Windows, то можете воспользоваться и «Блокнотом» (Notepad), который уже установлен в этой операционной системе (MS Word использовать не стоит). Достаточно написать в нем код, сохранить файл и изменить расширение с .txt на .py.
Если вы не видите расширения файлов, в «Проводнике» нажмите на вкладку «Вид» и поставьте галочку напротив «Расширения имен файлов».
При этом гораздо удобнее писать код в специально предназначенных для этого редакторах. Приведу ссылки на несколько популярных программ.
На сегодняшнем занятии мы будем использовать Atom.
Примечание. Редактор Atom был архивирован 3 марта 2023 года. Используйте два других редактора. Логика работы в каждом из них остается примерно той же.
Редактор Atom
После установки и запуска редактора Atom закройте ненужные вкладки и нажмите File → New File.
Затем, чтобы сообщить редактору, что мы хотим писать код на Питоне, сохраним этот файл с расширением .py. Для этого нажмем File → Save As и сохраним файл, например, под именем script.py на Рабочий стол.

Благодаря расширению .py Atom будет знать, что в файле script.py мы собираемся писать код на Питоне.
Шаг 2. Написать программу на Питоне
Первой программой будет алгоритм линейного поиска (linear search algorithm). Этот алгоритм проверяет наличие числа в массиве путем простого перебора всех значений от первого до последнего.

Напишем такую программу в редакторе Atom и сохраним файл script.py.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# возьмем массив, arr = [3, 7, 0, 2, 5] # в котором нам нужно найти число 2 x = 2 # в цикле пройдемся по индексу массива for i in range(len(arr)): # если искомое число находится на этом индексе if (arr[i] == x): # выведем индекс print(i) |
Если у вас не получилось создать файл в редакторе Atom, вы можете его скачать.
В результате исполнения этого кода компьютер должен выдать цифру три, потому что искомое число два находится именно под этим индексом. Посмотрим, так ли это.
Шаг 3. Запустить программу из командной строки
Запустим этот код с помощью командной строки.
- Откроем командную строку через клавиши Window + R → cmd. Перейдем на Рабочий стол (напомню, файл script.py мы сохранили именно туда) с помощью команды cd Desktop.
Команда cd (change directory) позволяет перейти в другую папку, а Desktop — это Рабочий стол, то есть название той папки, куда мы хотим перейти. В результате командная строка должна выглядеть вот так:

- Теперь просто введите script.py. Так мы вызовем интерпретатор и исполним код.
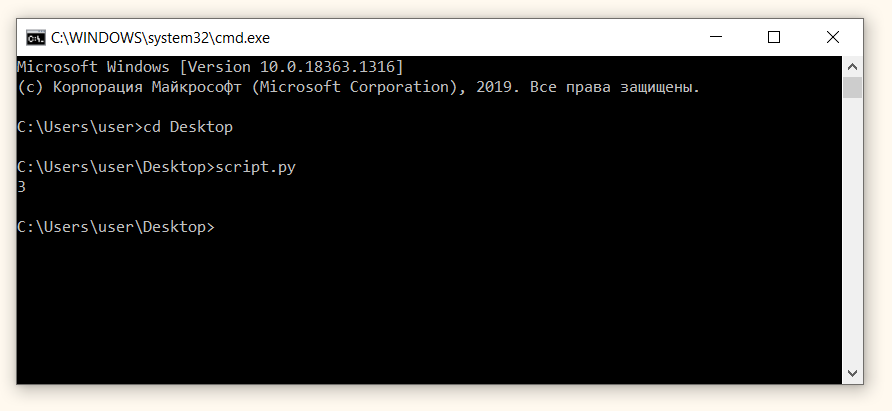
Все, наша первая программа на Питоне готова.
Установка библиотек
Как уже было сказано, по умолчанию, с сайта www.python.org устанавливается лишь базовый функционал. Если мы хотим использовать, например, библиотеку Numpy или библиотеку Matplotlib нам нужно установить их отдельно. В этом нам поможет программа pip.
Программа pip
pip — это программа, которая помогает устанавливать (обновлять и удалять) дополнительные библиотеки на вашем компьютере. По сути эта программа связывается с репозиторием (хранилищем) пакетов/библиотек Python Package Index или PyPI (pypi.org⧉) и скачивает запрашиваемые файлы.
Все действия осуществляются из командной строки.
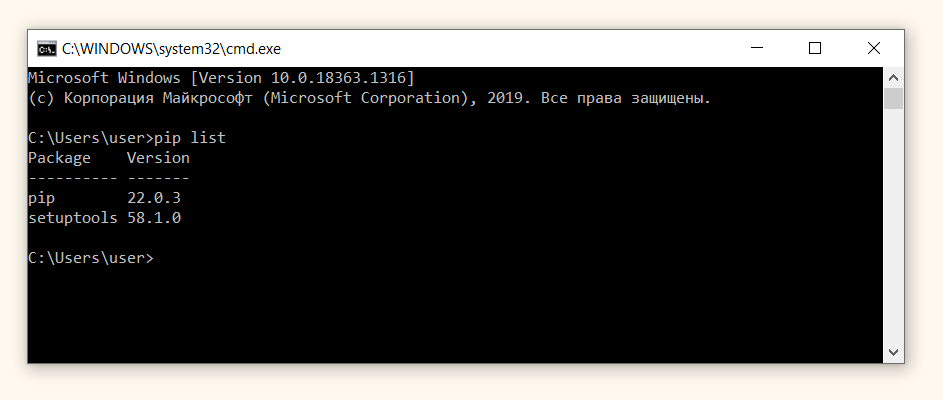
Если вы устанавливали Питон в соответствии с приведенной выше инструкцией, то pip уже присутствует на вашем компьютере. Проверить это можно с помощью команды pip --version.

Кроме того, мы можем посмотреть на список всех установленных на компьютере библиотек через команду pip list.
Установка библиотеки Numpy через pip install
Установим библиотеку Numpy. Для этого введем в командной строке pip install numpy.

Проверить установку отдельного пакета можно с помощью команды pip show numpy.

Использование установленной библиотеки
Теперь мы можем использовать установленную библиотеку Numpy внутри командной строки. Вначале перейдем в интерактивный режим с помощью команды py. После этого построчно (каждый раз нажимая Enter) введем следующие команды:
|
1 2 3 |
import numpy as np arr=np.array([1, 2, 3]) type(arr) |
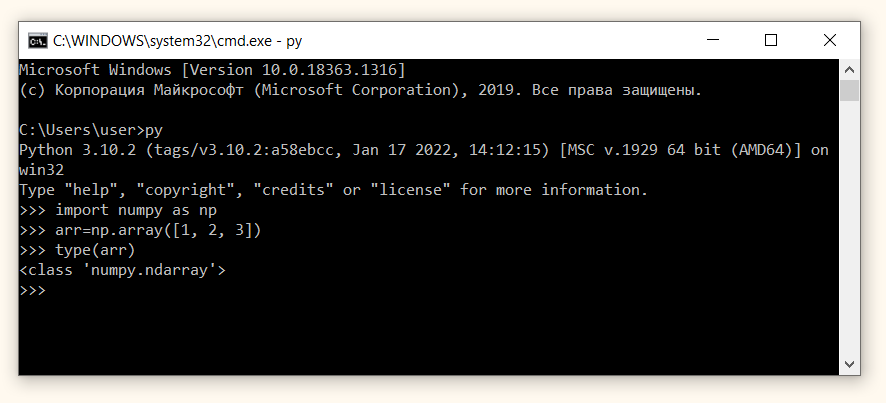
Как мы видим, в результате исполнения этого кода Питон успешно создал массив Numpy.
Обновление и удаление библиотек
Создатели библиотек периодически вносят в них обновления, и эти обновления полезно скачивать на свой компьютер. Воспользуйтесь следующей командой: pip install --upgrade numpy.

Для удаления пакета введите команду pip uninstall numpy.

В процессе удаления будет нужно нажать Y + Enter для подтверждения операции. Другие библиотеки устанавливаются, обновляются и удаляются точно так же.
Модуль в Питоне
Помимо использования Питона в интерактивном режиме и запуска кода из файла мы можем создавать собственные модули.
Модуль в Питоне — это программа на Питоне (файл с расширением .py), которую мы можем использовать в других программах с помощью команды import.
Создание собственного модуля может быть полезно, если вы написали код, который затем будете много раз использовать в других программах.
Создание собственного модуля
Наш первый модуль на Питоне будет состоять из двух алгоритмов поиска: линейного и бинарного.
Алгоритм линейного поиска
Алгоритм линейного поиска у нас уже готов. Достаточно «обернуть» его в функцию.
|
1 2 3 4 5 |
# объявим функцию linear() def linear(arr, x): for i in range(len(arr)): if arr[i] == x: return i |
Теперь перейдем к бинарному поиску.
Алгоритм бинарного поиска
Вначале поговорим о том, что такое бинарный поиск. Представьте, что у вас есть телефонная книга, и вам нужно найти номер телефона определенного человека.

Если фамилия этого человека начинается с буквы «А», то мы довольно быстро найдем его номер, используя уже известный нам алгоритм линейного поиска. А если он Яковлев? Линейному поиску придется перебрать все буквы от «А» до «Я».
Бинарный же поиск действует иначе. Вначале мы открываем книгу посередине, скажем, на букве «П».
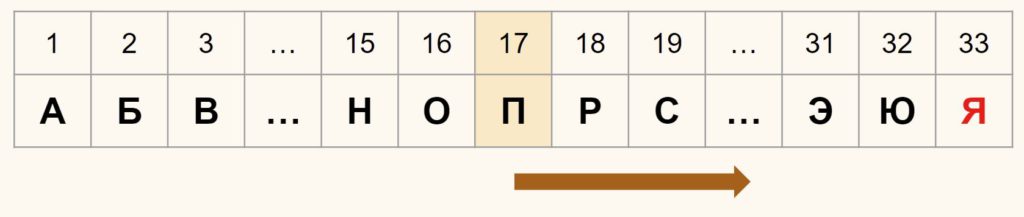
После этого мы посмотрим, находится ли буква «Я» в первой или во второй половине книги. Так как «Я» очевидно находится во второй половине справочника, мы разобьем пополам вторую половину. И снова посмотрим справа искомая буква или слева.

Так мы будем действовать до тех пор, пока не найдем нужную нам букву.
Важно, что в случае бинарного поиска элементы всегда упорядочены.
Напишем код такого алгоритма на Питоне, только поиск будем выполнять не по буквам, а по числам.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
# создадим класс BinarySearch class BinarySearch: # метод __init__() пропишем, но оставим пустым def __init__(self): pass # метод .srt() будет сортировать список чисел def srt(self, arr): # для этого мы используем функцию sorted() arr = sorted(arr) return arr # сам бинарный поиск будет выполняться через метод .check() def check(self, arr, x): # вначале зададим индексы первого и последнего значений # отсортированного списка low, high = 0, len(arr)-1 # цикл while будет длиться до тех пор, пока индекс последнего значения # больше или равен первому while low <= high: # найдем индекс среднего значения списка mid = low + (high - low) // 2 # если число с этим индексом равно искомому, if arr[mid] == x: # вернем этот индекс return mid # если меньше искомого (число "справа" от середины) elif arr[mid] < x: # новым нижним индексом будет "середина + 1" low = mid + 1 # если больше искомого (число "слева" от середины) else: # новым верхним индексом будет "середина - 1" high = mid - 1 # если число так и не найдено, вернем -1 mid = -1 return mid |
Хотя это уводит нас в сторону от темы сегодняшнего занятия, поясню код нахождения индекса среднего значения списка.
|
1 |
mid = low + (high - low) // 2 |
На первый взгляд индекс среднего значения можно найти вот так
|
1 |
(high + low) // 2 |
Однако первый вариант расчета индекса среднего значения позволяет избежать переполнения памяти (memory overflow) при использовании слишком больших значений.
Также замечу, что мы используем оператор целочисленного деления //, потому что в Питоне результатом обычного деления является число с плавающей точкой (float). Индекс же таким числом быть не может.
Полностью код для обоих алгоритмов будет выглядеть следующим образом.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
def linear(arr, x): for i in range(len(arr)): if arr[i] == x: return i class BinarySearch: def __init__(self): pass def srt(self, arr): arr = sorted(arr) return arr def check(self, arr, x): low, high = 0, len(arr)-1 while low <= high: mid = low + (high - low) // 2 if arr[mid] == x: return mid elif arr[mid] < x: low = mid + 1 else: high = mid - 1 mid = -1 return mid |
Документирование кода с помощью docstrings
До сих пор мы писали комментарии, которые помогали нам разобраться в том, как работает та или иная часть кода. При этом, такие комментарии при исполнении кода полностью пропадают.
Одновременно в Питоне существуют так называемые строки документации (docstrings). Они используются для описания работы функции, метода, класса или модуля. Доступ к ним можно получить через атрибут __doc__ или функцию help().
В чем основные особенности создания docstrings?
- Docstrings заключаются в тройные одинарные или двойные кавычки;
- Их следует располагать сразу после объявления функции, метода, класса или модуля.
Добавим соответствующие docstrings в только что созданный нами модуль и параллельно разберем основные принципы написания документации. Начнем с модуля в целом.
Строки документации для модуля в Питоне
Документация модуля описывает модуль и перечисляет все доступные функции и классы. Например, для модуля mymodule документация могла бы выглядеть следующим образом.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
""" Модуль для поиска элементов в массиве чисел. ============================================ Classes ------- BinarySearch Functions --------- linear """ |
Строки документации для функции описывают саму функцию, параметры и возвращаемое значение. Напишем документацию к функции linear().
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
def linear(arr, x): """Выполняет линейный поиск по массиву чисел. Parameters ---------- arr : {list, ndarray} Массив чисел, по которому выполняется поиск. x : int Искомое число. Returns ------- i : int Индекс искомого числа, если оно присутствует в массиве. """ for i in range(len(arr)): if arr[i] == x: return i |
Строки документации для класса описывают сам класс, а также перечисляют доступные атрибуты и методы. Каждый метод внутри класса сопровождается отдельной документацией.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
class BinarySearch: """Бинарный поиск по массиву чисел. """ def __init__(self): pass def srt(self, arr): """Сортирует массив чисел в возрастающем порядке. Parameters ---------- arr : {list, ndarray} Массив для сортировки. Returns ------- arr : {list, ndarray} Массив, отсортированный в возрастающем порядке. """ arr = sorted(arr) return arr def check(self, arr, x): """Проверяет наличие числа в массиве c помощью алгоритма бинарного поиска. Parameters ---------- arr : {list, numpy array} Массив чисел, по которому выполняется поиск. x : int Искомое число. Returns ------- mid : int Индекс числа в отсортированном по возрастанию массиве чисел. Возвращает -1, если число не найдено. """ low, high = 0, len(arr)-1 while low <= high: mid = low + (high - low) // 2 if arr[mid] == x: return mid elif arr[mid] < x: low = mid + 1 else: high = mid - 1 mid = -1 return mid |
Полностью снабженный документацией модуль выглядит следующим образом.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 |
""" Модуль для поиска элементов в массиве чисел. ============================================ Classes ------- BinarySearch Functions --------- linear """ def linear(arr, x): """Выполняет линейный поиск по массиву чисел. Parameters ---------- arr : {list, ndarray} Массив чисел, по которому выполняется поиск. x : int Искомое число. Returns ------- i : int Индекс искомого числа, если оно присутствует в массиве. """ for i in range(len(arr)): if arr[i] == x: return i class BinarySearch: """Бинарный поиск по массиву чисел. """ def __init__(self): pass def srt(self, arr): """Сортирует массив чисел в возрастающем порядке. Parameters ---------- arr : {list, ndarray} Массив для сортировки. Returns ------- arr : {list, ndarray} Массив, отсортированный в возрастающем порядке. """ arr = sorted(arr) return arr def check(self, arr, x): """Проверяет наличие числа в массиве c помощью алгоритма бинарного поиска. Parameters ---------- arr : {list, numpy array} Массив чисел, по которому выполняется поиск. x : int Искомое число. Returns ------- mid : int Индекс числа в отсортированном по возрастанию массиве чисел. Возвращает -1, если число не найдено. """ low, high = 0, len(arr)-1 while low <= high: mid = low + (high - low) // 2 if arr[mid] == x: return mid elif arr[mid] < x: low = mid + 1 else: high = mid - 1 mid = -1 return mid |
Замечу, что в данном случае мы использовали стиль документирования Numpy (NumPy documentation style). Он используется во многих известных пакетах: NumPy, SciPy, Pandas или, например, Scikit-Learn. При этом существуют и другие стили документирования.
Сохраним этот файл под именем mymodule.py. Все, наш модуль готов. Если у вас не получилось создать этот файл, вы можете скачать его по ссылке ниже.
Создание документации с помощью Pyment
Дополнительно замечу, что шаблон или «каркас» документации можно создать с помощью специального пакета Pyment. Для этого:
- Скачайте пакет Pyment через pip install pyment
- Убедитесь, что командная строка указывает на ту папку, в которой находится ваш модуль mymodule.py (например, на Рабочий стол)
- Введите команду pyment -w -o numpydoc mymodule.py. В данном случае вы буквально просите pyment создать документацию в стиле Numpy в файле под названием mymodule.py
- Откройте файл в редакторе кода и начинайте заполнять шаблон.
Загрузка и импорт модуля в Google Colab
Откроем ноутбук к этому занятию⧉
Давайте подгрузим файл mymodule.py в сессионное хранилище Google Colab.

Теперь мы можем работать с этим модулем так, как мы работали с функциями модуля random или классами библиотеки sklearn.
Вначале импортируем функцию linear() из модуля mymodule.
|
1 |
from mymodule import linear |
Создадим список, по которому будет выполняться поиск, а также искомое число.
|
1 2 |
arr = [3, 7, 0, 2, 5] target = 2 |
Вызовем функцию linear() и передадим ей список и целевое значение в качестве аргументов.
|
1 |
linear(arr, target) |
|
1 |
3 |
Теперь возьмем список большего размера и другое целевое значение.
|
1 2 |
arr = [9, 3, 343, 5, 8, 1, 20111, 32, 11, 6, 4] target = 9 |
Импортируем модуль mymodule под псевдонимом mm.
|
1 |
import mymodule as mm |
Воспользуемся бинарным поиском. Для этого вначале создадим объект класса BinarySearch и поместим его в переменную src.
|
1 |
src = mm.BinarySearch() |
Прежде чем выполнить поиск нам необходимо отсортировать список чисел. Вызовем метод .srt() класса BinarySearch.
|
1 2 3 4 5 |
# передадим методу .srt() список arr для сортировки sorted_arr = srch.srt(arr) # посмотрим на результат sorted_arr |
|
1 |
[1, 3, 4, 5, 6, 8, 9, 11, 32, 343, 20111] |
Теперь воспользуемся методом .check(), чтобы проверить, присутствует ли в списке число девять.
|
1 2 |
# напомню, что индекс числа 9 мы будем отсчитывать с нуля src.check(sorted_arr, target) |
|
1 |
6 |
В отсортированном списке это число присутствует под индексом шесть.
Просмотр документации модуля
Вначале выведем документацию модуля в целом.
|
1 |
print(mm.__doc__) |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
Модуль для поиска элементов в массиве чисел. ============================================ Classes ------- BinarySearch Functions --------- linear |
Посмотрим на функию linear().
|
1 |
print(mm.linear.__doc__) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Выполняет линейный поиск по массиву чисел. Parameters ---------- arr : {list, ndarray} Массив чисел, по которому выполняется поиск. x : int Искомое число. Returns ------- i : int Индекс искомого числа, если оно присутствует в массиве. |
И класс BinarySearch.
|
1 |
print(mm.BinarySearch.__doc__) |
|
1 |
Бинарный поиск по массиву чисел. |
Мы также можем посмотреть документацию отдельного метода внутри класса.
|
1 |
print(mm.BinarySearch.srt.__doc__) |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
Сортирует массив чисел в возрастающем порядке. Parameters ---------- arr : {list, ndarray} Массив для сортировки. Returns ------- arr : {list, ndarray} Массив, отсортированный в возрастающем порядке. |
Напомню, что документацию можно также посмотреть с помощью функции help().
Импорт собственного модуля в командной строке
Модуль в Питоне не обязательно подгружать в Google Colab, его также можно импортировать локально в командной строке.
Когда в интерактивном режиме мы пытаемся импортировать модуль с помощью команды import, Питон начинает искать этот модуль в конкретных папках. Посмотреть, что это за папки можно с помощью встроенного в базовый функционал модуля sys. В интерактивном режиме (команда py) последовательно введите следующие команды.
|
1 2 |
import sys sys.path |

Обратите внимание, что первой в списке [''] указана текущая папка.
Если ваш модуль не находится в одной из этих папок, импортировать его не получится. Здесь есть два варианта: либо переместить файл в одну из указанных папок, либо добавить новую папку в переменную path.
Способ 1. Переместить файл в папку из списка
Текущая папка будет иметь адрес, похожий на C:\Users\user (замените user на имя вашей учетной записи). Введите этот адрес в Проводнике.

Переместите туда наш модуль mymodule.py. Теперь войдем в интерактивный режим (команда py) и импортируем модуль с помощью команды import. После этого создадим массив, целевую переменную и вызовем функцию linear().
|
1 2 3 4 |
import mymodule arr = [3, 7, 0, 2, 5] target = 2 mymodule.linear(arr, target) |

Как вы видите, мы смогли успешно импортировать наш модуль и использовать необходимую функцию.
Способ 2. Добавить новый путь (папку) в переменную path
Добавим Рабочий стол в список sys.path. Для этого прекрасно подойдет метод .append(), который мы использовали для обычных питоновских списков.
Например, добавим Desktop (Рабочий стол).

Не забудьте заменить user на имя пользователя на вашем компьютере, а также обратите внимание на двойные обратные косые черты \\ в абсолютном пути к папке Desktop.
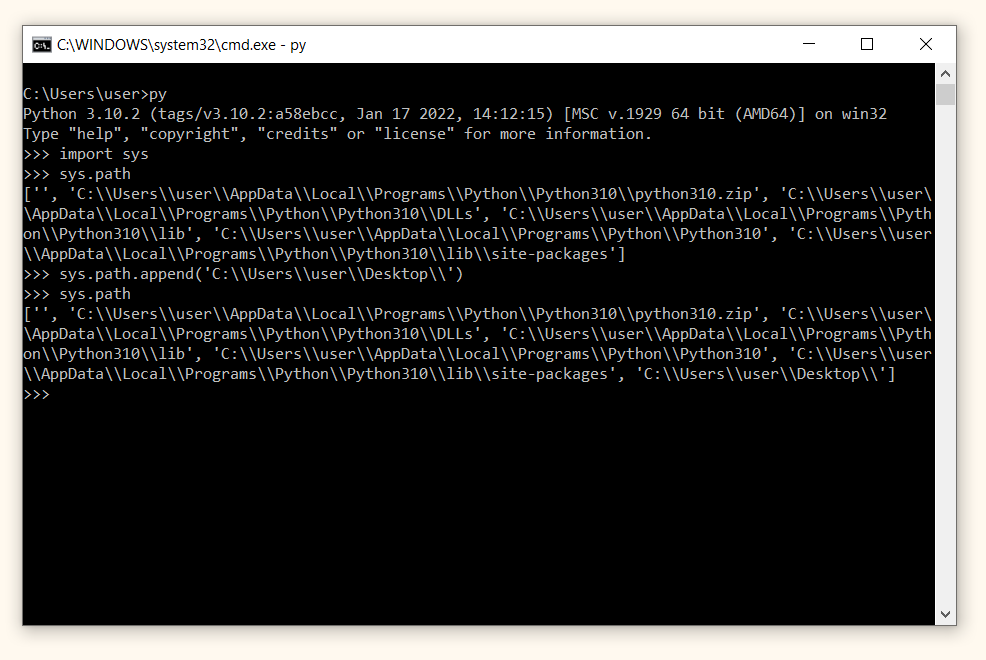
Мы готовы импортировать наш модуль с Рабочего стола. Вернем файл mymodule.py на Рабочий стол, войдем в интерактивный режим (команда py и последовательно введем код ниже.
|
1 2 3 4 |
import mymodule arr = [3, 7, 0, 2, 5] target = 2 mymodule.linear(arr, target) |

Нам снова удалось импортировать необходимую нам функцию linear().
Интерпретация и компиляция
Небольшое отступление от темы занятия. В самом начале мы сказали, что вместе с базовым функционалом Питона мы импортируем еще и интерпретатор. Давайте, разберемся, что это такое.
Как вы помните, компьютер понимает только нули и единицы, но никак не код на Питоне. Перевести понятный человеку язык программирования на машинный можно двумя способами: через компилятор (compiler) и через интерпретатор (interpreter).
Проведем следующую аналогию. Предположим, что у нас есть текст, скажем, на французском языке, и нам нужно понять, что в нем написано.
Компилятор
Первый вариант, отдать текст в бюро переводов. Там выполнят перевод всего документа и вернут текст на русском языке. Если в исходный текст внесут изменения, нам придется вновь заказывать его перевод. Можно сказать, что бюро переводов — это компилятор.
Компилятор берет файл с понятным человеку исходным кодом, переводит его в нули и единицы и сохраняет получившийся машинный код в исполняемом (executable) файле (на Windows — это файл с расширением .exe).

После этого мы можем запустить файл .exe и увидеть результат работы программы.
Интерпретатор
Интерпетатор действует иначе. Возвращаясь к аналогии с текстом на французском языке, вместо того чтобы отправлять документ в бюро переводов, мы просим человека, говорящего на этом языке на ходу, с листа передавать нам содержание текста.

Другими словами, интерпретатор — это программа, которая позволяет обрабатывать код и сразу выдавать результат.
Как следствие, языки делятся на компилируемые и интерпретируемые. Питон относится к интерпретируемым языкам, а, например, С — к компилируемым.
Впрочем, программа на Питоне может быть скомпилирована, например, с помощью пакета PyInstaller.
Кроме того, возможно вы обратили внимание, что когда мы вызывали модуль mymodule в командной строке, то Питон автоматически создал папку под названием __pycache__.pyc. В ней содержится скомпилированный байт-код программы (промежуточный код между Питоном и машинным языком), который ускоряет последующий запуск нашего модуля.
Пакет в Питоне
Поговорим про пакеты. Предположим, что вы создали довольно много полезных функций и классов и хранить их в одном модуле не слишком удобно. Самое время задуматься над созданием собственного пакета (package).

Примечание. Некоторые пакеты (например, Numpy или Pandas) принято называть библиотеками. При этом с технической точки зрения пакет и библиотека — это одно и то же.
Создание собственного пакета
В качестве упражнения создадим несложный пакет на Питоне и поместим его в тестовый репозиторий TestPyPI. Это своего рода «песочница», в которой можно научиться создавать пакеты перед их загрузкой в «большой» репозиторий PyPI.
Обратите внимание, PyPI и TestPyPI — это разные сайты, для которых требуются разные учетные записи.
Добавлю, что по большей части этот раздел создан на основе примера, приведенного в документации Питона⧉.
Шаг 1. Создание учетной записи
В первую очередь зарегистрируйтесь на сайте https://test.pypi.org/⧉.
Шаг 2. Создание файлов
Теперь создайте пакет example_package (по сути, набор папок и файлов) со следующей структурой.
|
1 2 3 4 5 |
base/ └── src/ └── example_package/ ├── __init__.py └── example_module.py |
В пакет мы поместим модуль example_module.py. В модуле объявим функцию для возведения числа в квадрат square().
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
""" Модуль для выполнения арифметических операций. ============================================ Functions --------- square """ def square(number): """Возводит число в квадрат. Parameters ---------- number : int Возводимое во вторую степень число. Returns ------- int Квадрат числа. """ return number ** 2 |
Также создадим пустой файл __init__.py. Он необходим для того, чтобы папка распознавалась именно как питоновский пакет.
Все последующие инструкции в командной строке будут выполняться из папки base/.
Например, если папка base/ находится на Рабочем столе, то перейти в нее можно с помощью команды cd Desktop\base.

Дополнительные файлы
Теперь давайте немного усложним структуру и добавим новые файлы.
|
1 2 3 4 5 6 7 8 9 |
base/ ├── LICENSE.txt ├── pyproject.toml ├── README.md ├── setup.py └── src/ └── example_package/ ├── __init__.py └── example_module.py |
- В файл pyproject.toml поместим следующий код:
|
1 2 3 |
[build-system] requires = ["setuptools>=42"] build-backend = "setuptools.build_meta" |
build-system.requires указывает на пакеты, необходимые для создания дистрибутива (то есть готового к распространению пакета), build-system.build-backend прописывает, какой объект будет использован для его создания.
- В setuptools.py содержится информация о пакете. Там же прописывается, какие файлы следует использовать при создании дистрибутива.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import setuptools with open("README.md", "r", encoding="utf-8") as fh: long_description = fh.read() setuptools.setup( name="example-package-DmitryMakarov", version="0.0.1", author="Dmitry Makarov", author_email="dm.v.makarov@gmail.com", description="Simple arithmetic package", long_description=long_description, long_description_content_type="text/markdown", url="https://github.com", project_urls={ "Bug Tracker": "https://github.com", }, classifiers=[ "Programming Language :: Python :: 3", "License :: OSI Approved :: MIT License", "Operating System :: OS Independent", ], package_dir={"": "src"}, packages=setuptools.find_packages(where="src"), python_requires=">=3.6", ) |
Вначале мы импортируем пакет setuptools. После этого открываем файл README.md и помещаем его содержимое в переменную longdescription.
Затем вызываем функцию setuptools.setup() и передаем ей целый ряд параметров. При создании собственного пакета замените значения следующих параметров:
- Название пакета (name). Оно должно быть уникальным. Для того чтобы обеспечить уникальность названия, проще всего добавить к нему свой логин на сайте https://test.pypi.org/ в формате «название-пакета-логин»;
- Также вы можете заменить поля author и author_email.
Менять остальные поля, в принципе, не обязательно.
- Файл README.md
В файле README.md содержатся описание пакета, примеры и технические детали проекта. Расширение .md указывает на то, что этот файл сохранен в формате markdown и поддерживает форматирование текста.
В документации на сайте www.markdownguide.org⧉ вы найдете рекомендации по использованию языка markdown.
В нашем файле мы напишем следующий текст.
|
1 2 3 4 5 |
# Тестовый пакет Файл README.md может содержать описание, примеры и технические детали пакета. Формат .md (markdown) поддерживает форматирование текста. Например, **полужирный шрифт** или *курсив*. Более полный перечень можно найти по [ссылке](https://guides.github.com/features/mastering-markdown/) |
- Файл LICENSE.txt
Остается создать файл с лицензией LICENSE.txt. Мы будем использовать лицензию открытого и свободного программного обеспечения MIT (Массачусетского технологического института).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
MIT License Copyright (c) 2022 Dmitry Makarov Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. |
Шаг 3. Создание дистрибутива
Скачаем инструменты, необходимые для создания дистрибутива.
|
1 |
pip install build |
Теперь из папки base/ введите команду py -m build. После ее выполнения должно появиться уведомление об успешном создании дистрибутива пакета.

Сам дистрибутив появится в папке base/.

Шаг 4. Подгрузка дистрибутива
Скачаем инструмент для подгрузки twine.
|
1 |
pip install twine |
И выполним подгрузку посредством следующей команды
|
1 |
py -m twine upload --repository testpypi dist/* |
Пароль при вводе отображаться не будет (ни в явном, ни в скрытом виде). Просто введите нужные символы и нажмите Enter.
Должен появиться вот такой результат.

Как вы видите, подгруженный пакет доступен по адресу: https://test.pypi.org/project/example-package-DmitryMakarov/0.0.1/⧉. Мы создали свой первый пакет.
Установка и использование пакета
Если вы захотите воспользоваться этим пакетом, то в командной строке введите команду, которая представлена на первой странице пакета.

|
1 |
pip install -i https://test.pypi.org/simple/ example-package-DmitryMakarov==0.0.1 |
Результат исполнения этой команды вы видите ниже.

Теперь мы можем пользоваться нашим пакетом. В интерактивном режиме (команду py) импортируем модуль example_module из пакета example_package и вызовем функцию square(), передав ей, например, число два.
|
1 2 |
from example_package import example_module example_module.square(2) |

В целом создание «взрослого» пакета на PyPI следует похожей схеме.
Подведем итог
Сегодня мы расширили наше представление о том, как запускать код на Питоне. Если раньше мы использовали только Google Colab, то теперь можем создавать собственные программы, модули и пакеты.
Вопросы для закрепления
Вопрос. Чем программа (скрипт) отличается от модуля?
Посмотреть правильный ответ
Ответ: технически и то, и другое — файл с расширением .py, при этом скрипт не предполагает его использования в других программах, а модуль предназначен именно для этого.
Вопрос. Зачем добавлять Питон в переменнаую окружения PATH в ОС Windows?
Посмотреть правильный ответ
Ответ: мы добавляем Питон в переменную PATH ОС Windows, чтобы в командной строке мы могли исполнять Питон в интерактивном режиме.
Вопрос. Что такое переменная path модуля sys в Питоне?
Посмотреть правильный ответ
Ответ: в переменной path модуля sys указаны те папки компьютера, в которых интерпретатор Питона будет искать файл для его импорта. Эта переменная отличается от переменной PATH в операционной системе.
Ответы на вопросы
Вопрос. Что такое if __name__ == '__main__':?
Ответ. Перед тем как исполнить код (например, в командной строке), интерпретатор Питона объявляет несколько переменных. Одна из них называется __name__. Этой переменной присваивается значение __main__. Создадим файл script.py со следующим кодом и запустим его в командной строке.
|
1 |
print(__name__) |
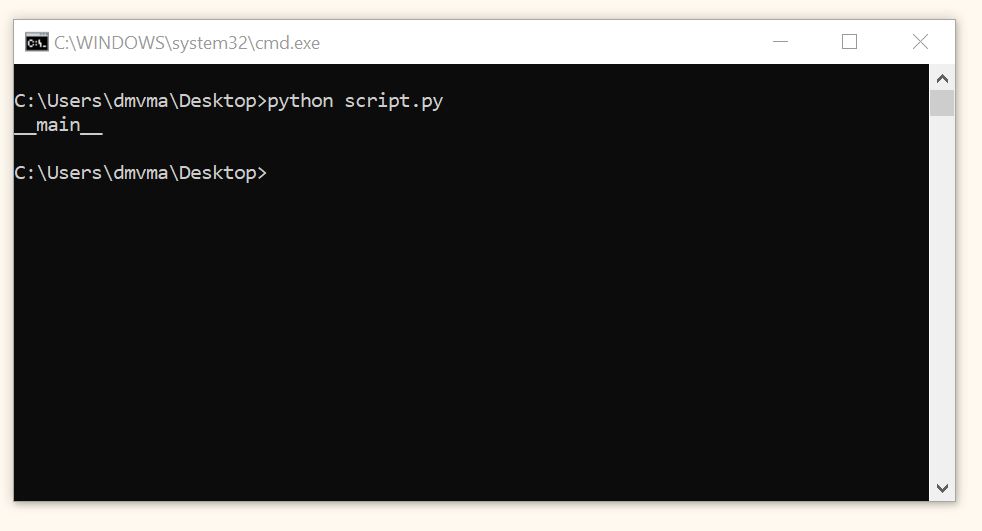
Теперь создадим еще один файл и назовем его module.py. Если вызвать его напрямую, то разумеется переменная __name__ также будет иметь значение __main__.
При этом если импортировать файл module.py внутри script.py, то значение переменной __name__ файла module.py изменится на его название (то есть слово module). Создадим файл module.py со следующим кодом.
|
1 |
print(__name__) |
Заменим код в файле script.py и исполним его.
|
1 2 3 |
import module print(__name__) |

Как мы получили такой результат? Сначала был импортирован код из файла module.py, внутри которого переменной __name__ было присвоено значение module. Именно это значение мы видим на первой строке вывода. Затем было выведено значение переменной __name__ файла script.py (то есть __main__).
Вероятно, чтобы лучше понять как работает приведенный в ответе код, имеет смысл самостоятельно прописать и исполнить каждый из примеров.
Теперь давайте изменим код файла module.py.
|
1 2 3 4 |
if __name__ == '__main__': print('This runs as the main file') else: print('This runs as an imported file') |
(1) Запустим его как основной файл напрямую из командной строки.

(2) Теперь импортируем его в script.py (код файла module.py оставим без изменений).
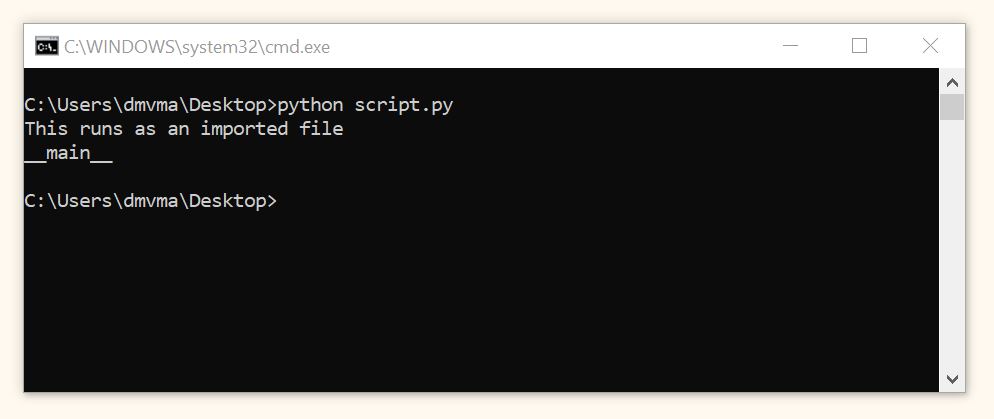
Как вы видите, в импортированном файле module.py переменная __name__ не содержит значения __main__, поэтому исполнилось выражение после else. В script.py переменная __name__ по-прежнему имеет значение __main__.
Зачем может быть нужно такое условие? Если вы пишете код, который в первую очередь предназначен для импорта (то есть модуль), будет разумно не вызывать содержащиеся в нем функции автоматически. В этом случае вызов функций можно заключить в обсуждаемое условие.
Изменим файл module.py.
|
1 2 3 4 5 |
def foo(): print('This is an imported function') if __name__ == '__main__': foo() |
Теперь внутри script.py вначале просто импортируем файл module.py.
|
1 |
import module |

При вызове модуля ничего не произошло. Так и должно быть. Для того чтобы вызвать функцию foo() нам нужно обратиться к ней напрямую. Изменим файл script.py и исполним его.
|
1 2 3 |
import module module.foo() |

На следующем занятии, как мы и планировали, мы посмотрим, как можно исполнять код на Питоне в программе Jupyter Notebook.