Все курсы > Программирование на Питоне > Занятие 14 (часть 1)
Программа Jupyter Notebook — это локальная программа, которая открывается в браузере и позволяет интерактивно исполнять код на Питоне, записанный в последовательности ячеек.

Облачной версией Jupyter Notobook является программа Google Colab, которой мы уже давно пользуемся на наших занятиях.
Начнем с установки Jupyter Notebook.
Как установить Jupyter Notebook
Способ 1. Если на вашем компьютере уже установлен Питон, то установить Jupyter Notebook можно через менеджер пакетов pip.
Способ 2 (рекомендуется). Кроме того, Jupyter Notebook входит в дистрибутив Питона под названием Anaconda.
На сегодняшнем занятии мы рассмотрим именно второй вариант установки.
Anaconda
Anaconda — это дистрибутив Питона и репозиторий пакетов, специально предназначенных для анализа данных и машинного обучения. Основу дистрибутива Anaconda составляет система управления пакетами и окружениями conda.
Conda можно управлять двумя способами, а именно через Anaconda Prompt — программу, аналогичную командной строке Windows, или через Anaconda Navigator — понятный графический интерфейс.
Кроме того, в дистрибутив Anaconda входит несколько полезных программ:
- Jupyter Notebook и JupyterLab — это программы, позволяющие исполнять код на Питоне (и, как мы увидим, на других языках) и обрабатывать данные.
- Spyder и PyCharm представляют собой так называемую интегрированную среду разработки (Integrated Development Environment, IDE). IDE — это редактор кода наподобие программы Atom или Sublime Text с дополнительными возможностями автодополнения, компиляции и интерпретации, анализа ошибок, отладки (debugging), подключения к базам данных и др.
- RStudio — интегрированная среда разработки для программирования на R.
На схеме структура Anaconda выглядит следующим образом:

Установка Anaconda на Windows
Шаг 1. Скачайте Anaconda⧉ с официального сайта.
Шаг 2. Запустите установщик.
На одном из шагов установки вам предложат поставить две галочки, в частности (1) добавить Anaconda в переменную path и (2) сделать дистрибутив Anaconda версией, которую Windows обнаруживает по умолчанию.
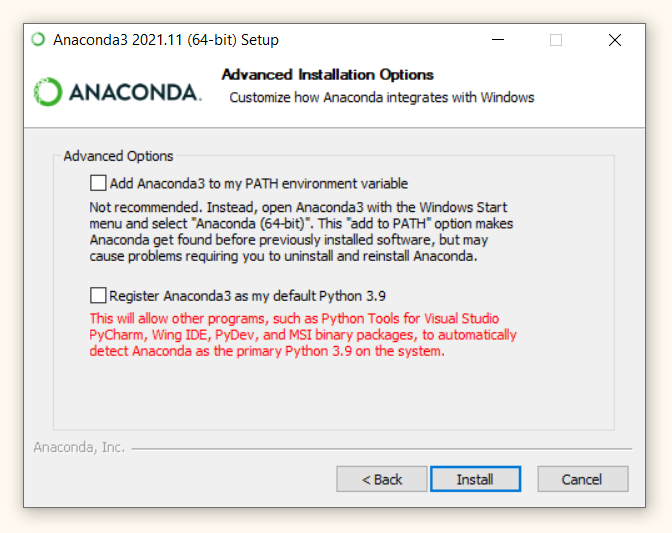
Не отмечайте ни один из пунктов!
Так вы сможете использовать два дистрибутива Питона, первый дистрибутив мы установили на прошлом занятии, второй — установим сейчас.
Как запустить Jupyter Notebook
После того как вы скачали и установили Anaconda, можно переходить к запуску ноутбука.
Шаг 1. Откройте Anaconda Navidator
Открыть Anaconda Navigator можно двумя способами.
Способ 1. Запуск из меню «Пуск». Просто перейдите в меню «Пуск» и выберите Anaconda Navigator.

Способ 2. Запуск через Anaconda Prompt. Также из меню «Пуск» откройте терминал Anaconda Prompt.

Введите команду anaconda-navigator.
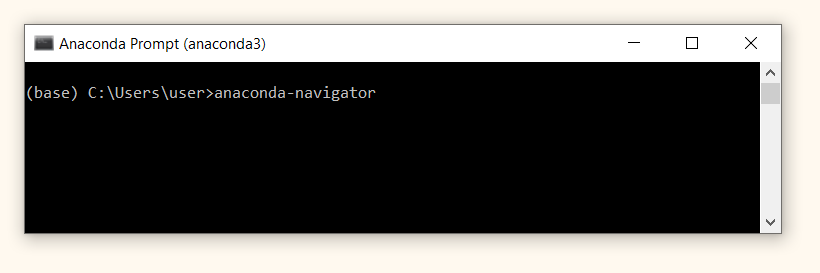
В результате должно появиться вот такое окно.

Шаг 2. Откройте Jupyter Notebook
Теперь выберите Jupyter Notebook и нажмите Launch («Запустить»).

Замечу, что Jupyter Notebook можно открыть не только из Anaconda Navigator, но и через меню «Пуск», а также введя в терминале Anaconda Prompt команду jupyter-notebook.
В результате должен запуститься локальный сервер, и в браузере откроется перечень папок вашего компьютера.

Шаг 3. Выберите папку и создайте ноутбук
Выберите папку, в которой хотите создать ноутбук. В моем случае я выберу Рабочий стол (Desktop).
Теперь в правом верхнем углу нажмите New → Python 3.

Мы готовы писать и исполнять код точно так же, как мы это делаем в Google Colab.
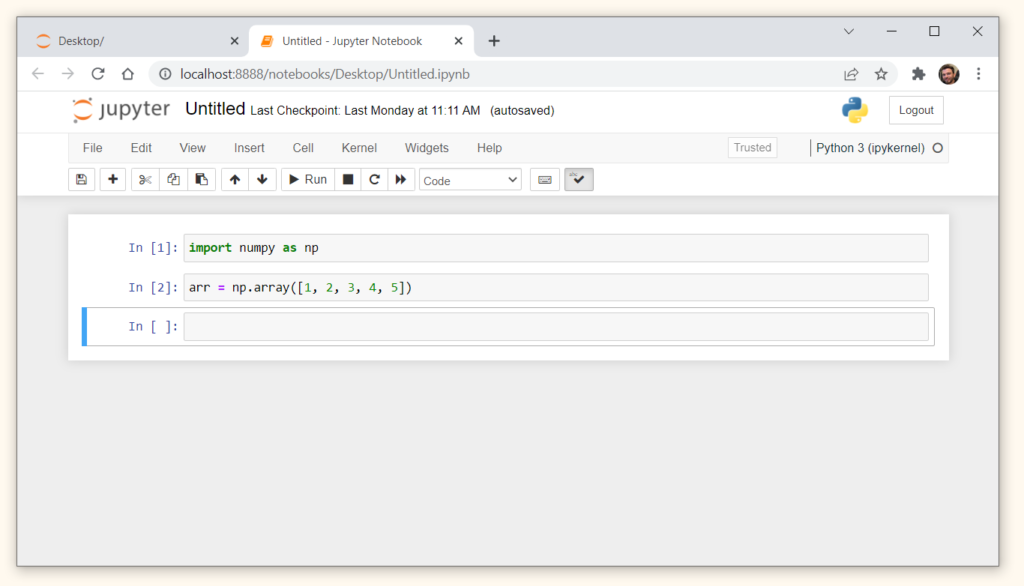
Импортируем библиотеку Numpy и создадим массив.
Шаг 4. Сохраните ноутбук и закройте Jupyter Notebook
Переименуйте ноутбук в mynotebook (для этого, как и в Google Colab, отредактируйте само название непосредственно в окне ноутбука). Сохранить файл можно через File → Save and Checkpoint.

Обратите внимание, помимо файла mynotebook.ipynb, Jupyter Notebook создал скрытую папку .ipynb_checkpoints. В ней хранятся файлы, которые позволяют вернуться к предыдущей сохраненной версии ноутбука (предыдущему check point). Сделать это можно, нажав File → Revert to Checkpoint и выбрав дату и время предыдущей сохраненной версии кода.
Когда вы закончили работу, закройте вкладку с ноутбуком. Остается прервать работу локального сервера, нажав Quit в правом верхнем углу.
После установки познакомимся поближе с особенностями Jupyter Notebook.