Все курсы > Программирование на Питоне > Занятие 14 (часть 2)
Во второй части занятия давайте подробнее поговорим про возможности Jupyter Notebook. Снова запустим только что созданный ноутбук любым удобным способом.
Код на Python
В целом мы пишем обычный код на Питоне.
Вкладка Cell
Для управления запуском или исполнением ячеек можно использовать вкладку Cell.

Здесь мы можем, в частности:
- Запускать ячейку и оставаться в ней же через Run Cells;
- Исполнять все ячейки в ноутбуке, выбрав Run All;
- Исполнять все ячейки выше (Run All Above) или ниже текущей (Run All Below);
- Очистить вывод ячеек, нажав All Output → Clear.
Вкладка Kernel
Командами вкладки Kernel мы управляем ядром (kernel) или вычислительным «движком» ноутбука.
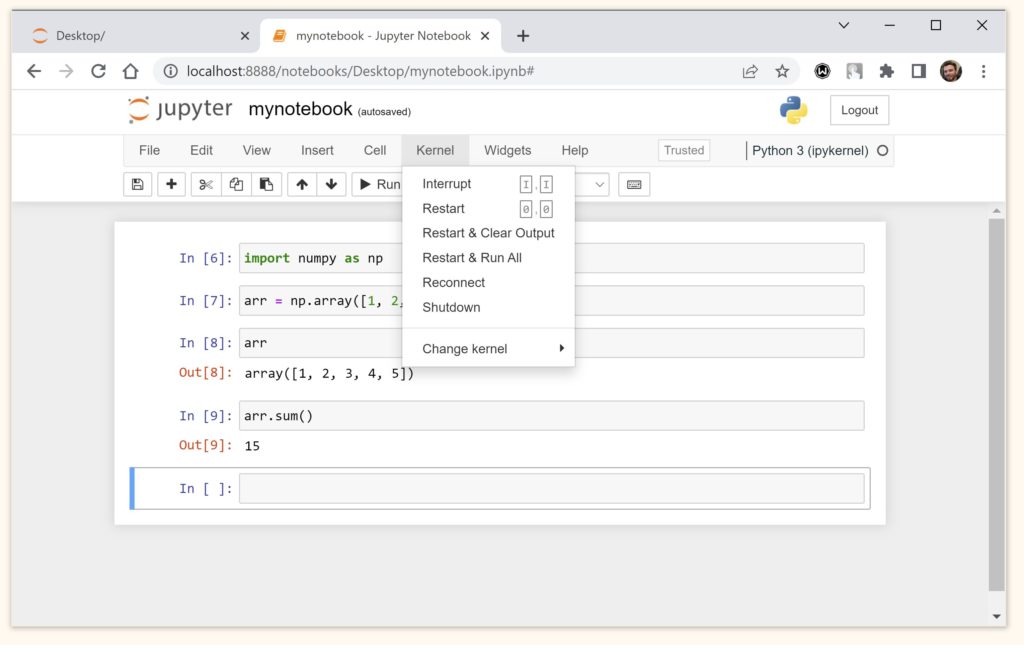
В этой вкладке мы можем, в частности:
- Прервать исполнение ячейки командой Interrupt. Это бывает полезно, если, например, исполнение кода занимает слишком много времени или в коде есть ошибка и исполнение кода не прервется самостоятельно.
- Перезапустить kernel можно командой Restart. Кроме того, можно
- очистить вывод (Restart & Clear Output); и
- заново запустить все ячейки (Restart & Run All).
Несколько слов про то, что такое ядро и как в целом функционирует Jupyter Notebook.

Пользователь взаимодействует с ноутбуком через браузер. Браузер в свою очередь отправляет запросы на сервер. Функция сервера заключается в том, чтобы загружать ноутбук и сохранять внесенные изменения в формате JSON с расширением .ipynb. Одновременно, сервер обращается к ядру в тот момент, когда необходимо обработать код на каком-либо языке (например, на Питоне).
Такое «разделение труда» между браузером, сервером и ядром позволяет во-первых, запускать Jupyter Notebook в любой операционной системе, во-вторых, в одной программе исполнять код на нескольких языках, и в-третьих, сохранять результат в файлах одного и того же формата.
Возможность программирования на нескольких языках (а значит использование нескольких ядер) мы изучим чуть позже, а пока посмотрим как устанавливать новые пакеты для Питона внутри Jupyter Notebook.
Установка новых пакетов
Установить новые пакеты в Anaconda можно непосредственно в ячейке, введя !pip install <package_name>. Например, попробуем установить Numpy.

Система сообщила нам, что такой пакет уже установлен. Более того, мы видим путь к папке внутри дистрибутива Anaconda, в которой Jupyter «нашел» Numpy.
При подготовке этого занятия я использовал два компьютера, поэтому имя пользователя на скриншотах указано как user или dmvma. На вашем компьютере при указании пути к файлу используйте ваше имя пользователя.
В последующих разделах мы рассмотрим дополнительные возможности по установке пакетов через Anaconda Prompt и Anaconda Navigator.
По ссылке ниже вы можете скачать код, который мы создали в Jupyter Notebook.
Два Питона на одном компьютере
Обращу ваше внимание, что на данный момент на моем компьютере (как и у вас, если вы проделали шаги прошлого занятия) установлено два Питона, один с сайта www.python.org⧉, второй — в составе дистрибутива Anaconda.
Посмотреть на установленные на компьютеры «Питоны» можно, набрав команду where python в Anaconda Prompt.

Указав полный или абсолютный путь (absolute path) к каждому из файлов python.exe, мы можем в интерактивном режиме исполнять код на версии 3.10 (установили с www.python.org) и на версии 3.8 (установили в составе Anaconda). При запуске файла python.exe из папки WindowsApps система предложит установить Питон из Microsoft Store.
В этом смысле нужно быть аккуратным и понимать, какой именно Питон вы используете и куда устанавливаете очередной пакет.
В нашем случае мы настроили работу так, чтобы устанавливать библиотеки для Питона с www.python.org через командную строку Windows, и устанавливать пакеты в Анаконду через Anaconda Prompt.
Убедиться в этом можно, проверив версии Питона через python --version в обеих программах.

Теперь попробуйте ввести в них команду pip list и сравнить установленные библиотеки.
Markdown в Jupyter Notebook
Вернемся к Jupyter Notebook. Помимо ячеек с кодом, можно использовать текстовые ячейки, в которых поддерживается язык разметки Markdown. Мы уже коротко рассмотрели этот язык на прошлом занятии, когда создавали пакет на Питоне.
По большому счету с помощью несложных команд Markdown, вы говорите Jupyter как отформатировать ту или иную часть текста.
Рассмотрим несколько основных возможностей форматирования (для удобстства и в силу практически полного совпадения два последующих раздела приведены в ноутбуке Google Colab).
Откроем ноутбук к этому занятию⧉
Заголовки
Заголовки создаются с помощью символа решетки.
|
1 2 3 4 5 6 |
# Заголовок 1 ## Заголовок 2 ### Заголовок 3 #### Заголовок 4 ##### Заголовок 5 ###### Заголовок 6 |

Если перед первым символом решетки поставить знак \, Markdown просто выведет символы решетки.

Абзацы
Абзацы отделяются друг от друга пробелами.
|
1 2 3 |
Абзац 1 Абзац 2 |

Мы также можем разделять абзацы прямой линией.
|
1 |
--- |

Выделение текста
|
1 2 3 4 5 |
**Полужирный стиль** *Курсив* ~~Перечеркнутый стиль~~ |

Форматирование кода и выделенные абзацы
Мы можем выделять код внутри строки или отдельным абзацем.
|
1 2 3 4 |
Отформатируем код `print('Hello world!')` внутри строки и отдельным абзацем ``` print('Hello world!') ``` |

Возможно выделение и текстовых абзацев (так называемые blockquotes).
|
1 2 3 |
> Markdown позволяет форматировать текст без использования тэгов. > > Он был создан в 2004 году Джоном Грубером и Аароном Шварцем. |

Списки
Посмотрим на создание упорядоченных и неупорядоченных списков.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
**Упорядоченный список** 1. Пункт 1 1. Пункт 2 (нумерация ведется автоматически) **Неупорядоченный список** * Пункт 1.1 * Пункт 2.1 * Пункт 2.2 * Пункт 3.1 * Пункт 3.2 * Пункт 1.2 |

Ссылки и изображения
Текст ссылки заключается в квадратные скобки, сама ссылка — в круглые.
|
1 |
[сайт проекта Jupyter](https://jupyter.org/) |

Изображение форматируется похожим образом.
|
1 |
 |
Таблицы
|
1 2 3 4 5 |
| id | item | price | |--- |----------| ------| | 01 | pen | 200 | | 02 | pencil | 150 | | 03 | notebook | 300 | |
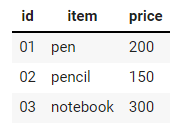
Таблицы для Markdown бывает удобно создавать с помощью специального инструмента⧉.
Формулы на LaTeX
В текстовых полях можно вставлять формулы и математические символы с помощью системы верстки, которая называется LaTeX (произносится «латэк»). Они заключаются в одинарные или двойные символы $.
Если использовать одинарный символ $, то расположенная внутри формула останется в пределах того же абзаца (inline formula). Например, запись $ y = x^2 $ даст $ y = x^2 $.
В то время как $$ y = x^2 $$ поместит формулу в новый абзац (display formula).
$$ y = x^2 $$
Одинарный символ \ добавляет пробел. Двойной символ \\ переводит текст на новую строку.
|
1 |
$$ \hat{y} = \theta_0 + \theta_1 x_1 + \theta_2 x_2 + \ \ ... \ \ + \\ \theta_n x_n $$ |

Рассмотрим некоторые элементы синтаксиса LaTeX.
Форматирование текста
|
1 2 3 4 5 6 7 |
$ \text{just text} $ $ \textbf{bold} $ $ \textit{italic} $ $ \underline{undeline} $ |

Надстрочные и подстрочные знаки
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
hat $ \hat{x} $ bar $ \bar{x} $ vector $ \vec{x} $ tilde $ \tilde{x} $ superscript $ e^{ax + b} $ subscript $ A_{i, j} $ degree $ 90^{\circ} $ |

Скобки
Вначале рассмотрим код для скобок в пределах высоты строки.
|
1 2 3 4 5 6 7 8 |
$$ (a+b) \\ [a+b] \\ \{a+b\} \\ \langle x+y \rangle \\ |x+y| \\ \|x+y\| $$ |
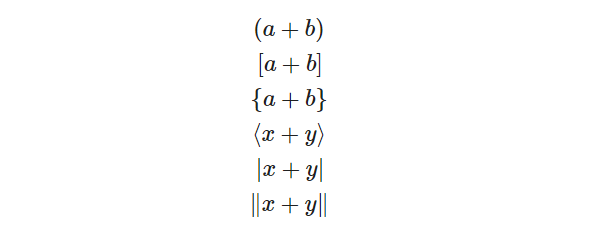
Кроме того, с помощью \left(, \right), а также \left[, \right] и так далее можно увеличить высоту скобки. Сравните.
|
1 2 3 |
$$ \left(\frac{1}{2}\right) \qquad (\frac{1}{2}) $$ |

Также можно использовать отдельные команды для скобок различного размера.
|
1 2 3 4 5 |
$$ \big( \Big( \bigg( \Bigg( \\ \big] \Big] \bigg] \Bigg] \\ \big\{ \Big\{ \bigg\{ \Bigg\{ $$ |

Дробь и квадратный корень
|
1 2 3 4 5 |
fraction $$ \frac{1}{1+e^{-z}} $$ square root $ \sqrt{\sigma^2} $ |
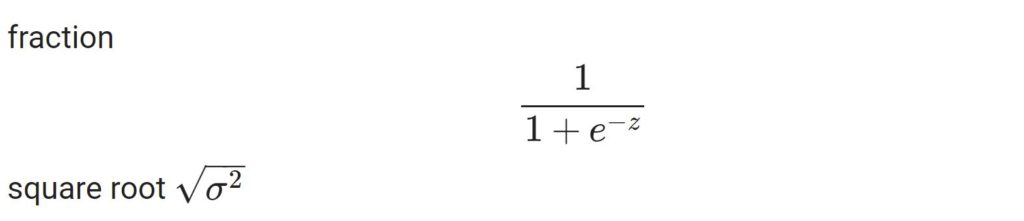
Греческие буквы
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
|Uppercase | LaTeX |Lowercase | LaTeX | RU | |--------- |------- |--------- |------- |-------- | |--------- |------- |$\alpha$ |\\alpha | альфа | |--------- |------- |$\beta$ |\\beta | бета | |$\Gamma$ |\\Gamma |$\gamma$ |\\gamma | гамма | |$\Delta$ |\\Delta |$\delta$ |\\delta | дельта | |--------- |------- |$\epsilon$ |\\epsilon | эпсилон | |--------- |------- |$\varepsilon$ |\\varepsilon | ------- | |--------- |------- |$\zeta$ |\\zeta | дзета | |--------- |------- |$\eta$ |\\eta | эта | |$\Theta$ |\\Theta |$\theta$ |\\theta | тета | |--------- |------- |$\vartheta$ |\\vartheta | ------- | |--------- |------- |$\iota$ |\\iota | йота | |--------- |------- |$\kappa$ |\\kappa | каппа | |$\Lambda$ |\\Lambda |$\lambda$ |\\lambda | лямбда | |--------- |------- |$\mu$ |\\mu | мю | |--------- |------- |$\nu$ |\\nu | ню | |$\Xi$ |\\Xi |$\xi$ |\\xi | кси | |--------- |------- |$\omicron$ |\\omicron | омикрон | |$\Pi$ |\\Pi |$\pi$ |\\pi | пи | |--------- |------- |$\varpi$ |\\varpi | ------- | |--------- |------- |$\rho$ |\\rho | ро | |--------- |------- |$\varrho$ |\\varrho | ------- | |$\Sigma$ |\\Sigma |$\sigma$ |\\sigma | сигма | |--------- |------- |$\varsigma$ |\\varsigma | ------- | |--------- |------- |$\tau$ |\\tau | тау | |$\Upsilon$ |\\Upsilon |$\upsilon$ |\\upsilon | ипсилон | |$\Phi$ |\\Phi |$\phi$ |\\phi | фи | |--------- |------- |$\varphi$ |\\varphi | ------- | |--------- |------- |$\chi$ |\\chi | хи | |$\Psi$ |\\Psi |$\psi$ |\\psi | пси | |$\Omega$ |\\Omega |$\omega$ |\\omega | омега | |


Латинские обозначения
|
1 2 3 4 5 6 |
$$ \sin(-\alpha) = -\sin(\alpha) \\ \cos(\theta)=\sin \left( \frac{\pi}{2}-\theta \right) \\ \tan(x) = \frac{\sin(x)}{\cos(x)} \\ \log_b(1) = 0 \\ $$ |
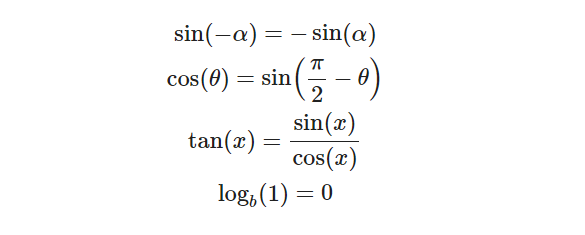
Логические символы и символы множества
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
| LaTeX | symbol | | ---------------------- | ------------------------- | |\Rightarrow | $ \Rightarrow $ | |\rightarrow | $ \rightarrow $ | |\longleftrightarrow | $ \Leftrightarrow $ | |\cap | $ \cap $ | |\cup | $ \cup $ | |\subset | $ \subset $ | |\in | $ \in $ | |\notin | $ \notin $ | |\varnothing | $ \varnothing $ | |\neg | $ \neg $ | |\forall | $ \forall $ | |\exists | $ \exists $ | |\mathbb{N} | $ \mathbb{N} $ | |\mathbb{Z} | $ \mathbb{Z} $ | |\mathbb{Q} | $ \mathbb{Q} $ | |\mathbb{R} | $ \mathbb{R} $ | |\mathbb{C} | $ \mathbb{C} $ | |

Другие символы
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
| LaTeX | symbol | | ---------------------- | ------------------------- | | < | $ < $ | | \leq | $ \leq $ | | > | $ \geq $ | | \neq | $ \neq $ | | \approx | $ \approx $ | | \angle | $ \angle $ | | \parallel | $ \parallel $ | | \pm | $ \pm $ | | \mp | $ \mp $ | | \cdot | $ \cdot $ | | \times | $ \times $ | | \div | $ \div $ | |

Кусочная функция и система уравнений
Посмотрим на запись функции sgn (sign function) средствами LaTeX.
|
1 2 3 4 5 6 7 8 9 |
$$ sgn(x) = \left\{ \begin{array}\\ 1 & \mbox{if } \ x \in \mathbf{N}^* \\ 0 & \mbox{if } \ x = 0 \\ -1 & \mbox{else.} \end{array} \right. $$ |

Схожим образом записывается система линейных уравнений.
|
1 2 3 4 5 6 7 8 |
$$ \left\{ \begin{matrix} 4x + 3y = 20 \\ -5x + 9y = 26 \end{matrix} \right. $$ |

Горизонтальная фигурная скобка
|
1 2 3 4 5 6 |
$$ \overbrace{ \underbrace{a}_{real} + \underbrace{b}_{imaginary} i} ^{\textit{complex number}} $$ |
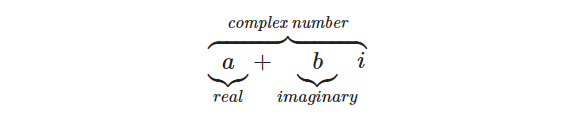
Предел, производная, интеграл
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
Пределы: $$ \lim_{x \to +\infty} f(x) $$ $$ \lim_{x \to -\infty} f(x) $$ $$ \lim_{x \to с} f(x) $$ Производная (нотация Лагранжа): $$ f'(x) $$ Частная производная (нотация Лейбница): $$ \frac{\partial f}{\partial x} $$ Градиент: $$ \nabla f(x_1, x_2) = \begin{bmatrix} \frac{\partial f}{\partial x_1} \\ \frac{\partial f}{\partial x_2} \end{bmatrix} $$ Интеграл: $$\int_{a}^b f(x)dx$$ |

Сумма и произведение
|
1 2 3 4 5 6 7 8 9 |
Сумма: $$ \sum\limits_{i=1}^n a_{i} $$ $$\sum_{i=1}^n a_{i} $$ Произведение: $$\prod_{j=1}^m a_{j}$$ |

Матрица
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
Без скобок (plain): $$ \begin{matrix} 1 & 2 & 3\\ a & b & c \end{matrix} $$ Круглые скобки (parentheses, round brackets): $$ \begin{pmatrix} 1 & 2 & 3\\ a & b & c \end{pmatrix} $$ Квадратные скобки (square brackets): $$ \begin{bmatrix} 1 & 2 & 3\\ a & b & c \end{bmatrix} $$ Фигурные скобки (curly brackets, braces): $$ \begin{Bmatrix} 1 & 2 & 3\\ a & b & c \end{Bmatrix} $$ Прямые скобки (pipes): $$ \begin{vmatrix} 1 & 2 & 3\\ a & b & c \end{vmatrix} $$ Двойные прямые скобки (double pipes): $$ \begin{Vmatrix} 1 & 2 & 3\\ a & b & c \end{Vmatrix} $$ |

Программирование на R
Jupyter Notebook позволяет писать код на других языках программирования, не только на Питоне. Попробуем написать и исполнить код на R, языке, который специально разрабатывался для data science.
Вначале нам понадобится установить kernel для R. Откроем Anaconda Prompt и введем следующую команду conda install -c r r-irkernel. В процессе установки система спросит продолжать или нет (Proceed ([y]/n)?). Нажмите y + Enter.
Откройте Jupyter Notebook. В списке файлов создайте ноутбук на R. Назовем его rprogramming.

После установки нового ядра и создания еще одного файла .ipynb схема работы нашего Jupyter Notebook немного изменилась.
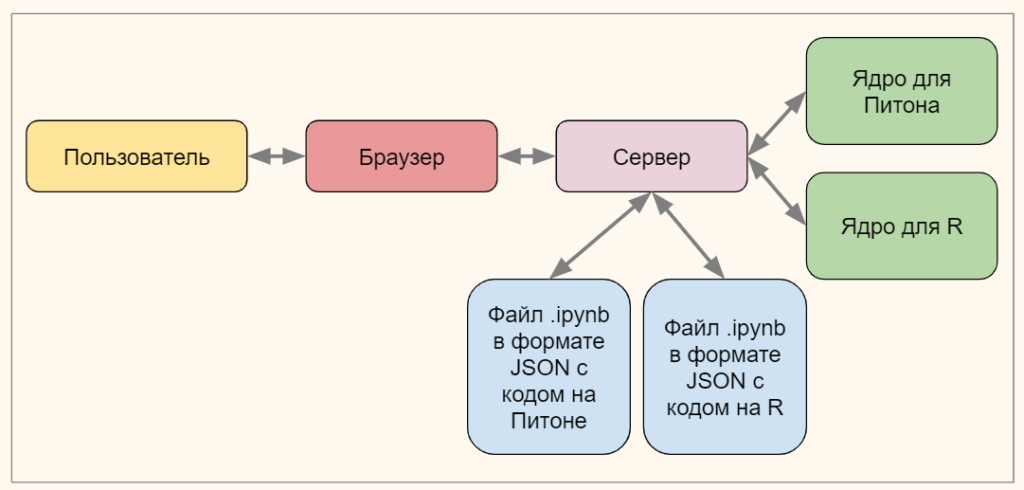
Теперь мы готовы писать код на R. Мы уже начали знакомиться с этим языком, когда изучали парадигмы программирования. Сегодня мы рассмотрим основные типы данных и особенности синтаксиса.
Переменные в R
Числовые, строковые и логические переменные
Как и в Питоне, в R мы можем создавать числовые (numeric), строковые (character) и логические (logical) переменные.
|
1 2 3 4 5 6 7 8 |
# поместим число 42 в переменную numeric_var numeric_var = 42 # строку поместим в переменную text_var text_var <- 'Hello world!' # наконец присвоим значение TRUE переменной logical_var TRUE -> logical_var |
Для присвоения значений можно использовать как оператор =, так и операторы присваивания <- и ->. Обратите внимание, используя -> мы можем поместить значение слева, а переменную справа.
Посмотрим на результат (в Jupyter Notebook можно обойтись без функции print()).
|
1 |
text_var |
|
1 |
'Hello world!' |
Выведем класс созданных нами объектов с помощью функции class().
|
1 2 3 |
class(numeric_var) class(text_var) class(logical_var) |
|
1 2 3 |
'numeric' 'character' 'logical' |
Тип данных можно посмотреть с помощью функции typeof().
|
1 2 3 |
typeof(numeric_var) typeof(text_var) typeof(logical_var) |
|
1 2 3 |
'double' 'character' 'logical' |
Хотя вывод этих функций очень похож, мы, тем не менее, видим, что классу numeric соответствует тип данных double (число с плавающей точкой с как минимум двумя знаками после запятой).
Числовые переменные: double и integer
По умолчанию, в R и целые числа, и дроби хранятся в формате double (сокращённое от double precision number, т.е. число двойной точности).
Тип данных double в R соответствует типу float в Питоне.
|
1 2 3 4 5 |
# еще раз поместим число 42 в переменную numeric_var numeric_var <- 42 # выведем тип данных typeof(numeric_var) |
|
1 |
'double' |
Принудительно перевести 42 в целочисленное значение можно с помощью функции as.integer().
|
1 2 |
int_var <- as.integer(numeric_var) typeof(int_var) |
|
1 |
'integer' |
Кроме того, если после числа поставить L, это число автоматически превратится в integer.
|
1 |
typeof(42L) |
|
1 |
'integer' |
Превратить integer обратно в double можно с помощью функций as.double() и as.numeric().
|
1 2 |
typeof(as.double(int_var)) typeof(as.numeric(42L)) |
|
1 2 |
'double' 'double' |
Если число хранится в формате строки, его можно перевести обратно в число (integer или double).
|
1 2 |
text_var <- '42' typeof(text_var) |
|
1 |
'character' |
|
1 2 |
typeof(as.numeric(text_var)) # можно также использовать as.double() typeof(as.integer(text_var)) |
|
1 2 |
'double' 'integer' |
Вектор
Вектор (vector) — это одномерная структура, которая может содержать множество элементов одного типа. Вектор можно создать с помощью функции c().
|
1 2 3 |
# создадим вектор с информацией о продажах товара в магазине за неделю (в тыс. рублей) sales <- c(24, 28, 32, 25, 30, 31, 29) sales |
|
1 |
24 28 32 25 30 31 29 |
С помощью функций length() и typeof() мы можем посмотреть соответственно общее количество элементов и тип данных каждого из них.
|
1 2 3 |
# посмотрим на общее количество элементов и тип данных каждого из них length(sales) typeof(sales) |
|
1 2 |
7 'double' |
У вектора есть индекс, который (в отличие, например, от списков в Питоне), начинается с единицы.
|
1 |
sales[1] |
|
1 |
24 |
При указании диапазона выводятся и первый, и последний его элементы.
|
1 |
sales[1:5] |
|
1 |
24 28 32 25 30 |
Отрицательный индекс убирает элементы из вектора.
|
1 |
sales[-5] |
|
1 |
24 28 32 25 31 29 |
Именованный вектор (named vector) создается с помощью функции names().
|
1 2 3 |
# создадим еще один вектор с названиями дней недели days_vector <- c('Понедельник', 'Вторник', 'Среда', 'Четверг', 'Пятница', 'Суббота', 'Воскресенье') days_vector |
|
1 |
'Понедельник' 'Вторник' 'Среда' 'Четверг' 'Пятница' 'Суббота' 'Воскресенье' |
|
1 2 3 |
# создадим именованный вектор с помощью функции names() names(sales) <- days_vector sales |
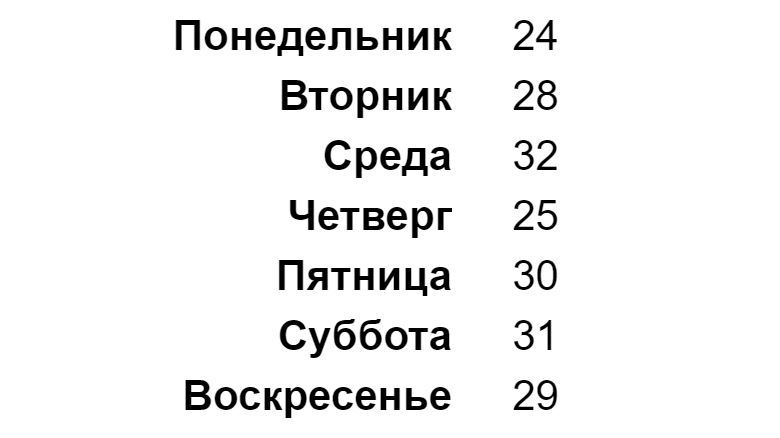
Выводить элементы именованного вектора можно не только по числовому индексу, но и по их названиям.
|
1 |
sales['Воскресенье'] |
|
1 |
Воскресенье: 29 |
Список
В отличие от вектора, список (list) может содержать множество элементов различных типов.
|
1 2 |
# список создается с помощью функции list() list('DS', 'ML', c(21, 24), c(TRUE, FALSE), 42.0) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
[[1]] [1] "DS" [[2]] [1] "ML" [[3]] [1] 21 24 [[4]] [1] TRUE FALSE [[5]] [1] 42 |
Матрица
Матрица (matrix) в R — это двумерная структура, содержащая одинаковый тип данных (чаще всего числовой). Матрица создается с помощью функции matrix() с параметрами data, nrow, ncol и byrow.
- data — данные для создания матрицы
- nrow и ncol — количество строк и столбцов
- byrow — параметр, указывающий заполнять ли элементы матрицы построчно (TRUE) или по столбцам (FALSE)
Рассмотрим несколько примеров. Cоздадим последовательность целых чисел (по сути, тоже вектор).
|
1 2 3 4 5 |
# для этого подойдет функция seq() sqn <- seq(1:9) sqn typeof(sqn) |
|
1 2 |
1 2 3 4 5 6 7 8 9 'integer' |
Используем эту последовательность для создания двух матриц.
|
1 2 3 |
# создадим матрицу, заполняя значения построчно mtx <- matrix(sqn, nrow = 3, ncol = 3, byrow = TRUE) mtx |

|
1 2 3 |
# теперь создадим матрицу, заполняя значения по столбцам mtx <- matrix(sqn, nrow = 3, ncol = 3, byrow = FALSE) mtx |

Зададим названия для строк и столбцов второй матрицы.
|
1 2 3 4 5 6 7 8 9 10 11 |
# создадим два вектора с названиями строк и столбцов rows <- c('Row 1', 'Row 2', 'Row 3') cols <- c('Col 1', 'Col 2', 'Col 3') # используем функции rownames() и colnames(), # чтобы передать эти названия нашей матрице rownames(mtx) <- rows colnames(mtx) <- cols # посмотрим на результат mtx |
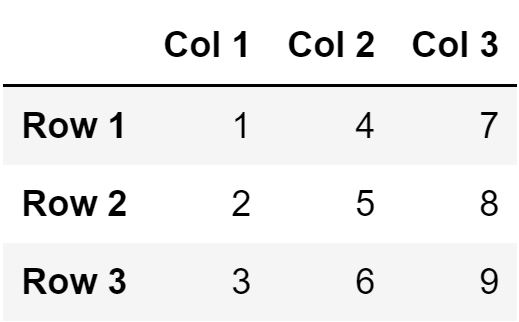
Посмотрим на размерность этой матрицы с помощью функции dim().
|
1 |
dim(mtx) |
|
1 |
3 3 |
Массив
В отличие от матрицы, массив (array) — это многомерная структура. Создадим трехмерный массив размерностью 3 х 2 х 3. Вначале создадим три матрицы размером 3 х 2.
|
1 2 3 4 5 |
# создадим три матрицы размером 3 х 2, # заполненные пятерками, шестерками и семерками a <- matrix(5, 3, 2) b <- matrix(6, 3, 2) c <- matrix(7, 3, 2) |
Теперь соединим их с помощью функции array(). Передадим этой функции два параметра в форме векторов: данные (data) и размерность (dim).
|
1 2 3 4 |
arr <- array(data = c(a, b, c), # вектор с матрицами dim = c(3, 2, 3)) # вектор размерности print(arr) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
, , 1 [,1] [,2] [1,] 5 5 [2,] 5 5 [3,] 5 5 , , 2 [,1] [,2] [1,] 6 6 [2,] 6 6 [3,] 6 6 , , 3 [,1] [,2] [1,] 7 7 [2,] 7 7 [3,] 7 7 |
Факторная переменная
Факторная переменная или фактор (factor) — специальная структура для хранения категориальных данных. Вначале немного теории.
Как мы узнаем на курсе анализа данных, категориальные данные бывают номинальными и порядковыми.
- Номинальные категориальные (nominal categorical) данные представлены категориями, в которых нет естественного внутреннего порядка. Например, пол или цвет волос человека, марка автомобиля могут быть отнесены к определенным категориям, но не могут быть упорядочены.
- Порядковые категориальные (ordinal categorical) данные наоборот обладают внутренним, свойственным им порядком. К таким данным относятся шкала удовлетворенности потребителей, класс железнодорожного билета, должность или звание, а также любая количественная переменная, разбитая на категории (например, низкий, средний и высокий уровень зарплат).
Посмотрим, как учесть такие данные с помощью R. Начнем с номинальных данных.
|
1 2 3 4 5 6 |
# предположим, что мы собрали данные о цветах нескольких автомобилей и поместили их в вектор color_vector <- c('blue', 'blue', 'white', 'black', 'yellow', 'white', 'white') # преобразуем этот вектор в фактор с помощью функции factor() factor_color <- factor(color_vector) factor_color |

Как вы видите, функция factor() разбила данные на категории, при этом эти категории остались неупорядоченными. Посмотрим на класс созданного объекта.
|
1 |
class(factor_color) |
|
1 |
'factor' |
Теперь поработаем с порядковыми данными.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# возьмем данные измерений температуры, выраженные категориями temperature_vector <- c('High', 'Low', 'High','Low', 'Medium', 'High', 'Low') # создадим фактор factor_temperature <- factor(temperature_vector, # указав параметр order = TRUE order = TRUE, # а также вектор упорядоченных категорий levels = c('Low', 'Medium', 'High')) # посмотрим на результат factor_temperature |

Выведем класс созданного объекта.
|
1 |
class(factor_temperature) |
|
1 |
'ordered' 'factor' |
Добавлю, что количество элементов в каждой из категорий можно посмотреть с помощью функции summary().
|
1 |
summary(factor_temperature) |

Датафрейм
Датафрейм в R выполняет примерно ту же функцию, что и в Питоне. С помощью функции data.frame() создадим простой датафрейм, где параметрами будут названия столбцов, а аргументами — векторы их значений.
|
1 2 3 4 5 |
df <- data.frame(city = c('Москва', 'Париж', 'Лондон'), population = c(12.7, 2.1, 8.9), country = c('Россия', 'Франция', 'Великобритания')) df |
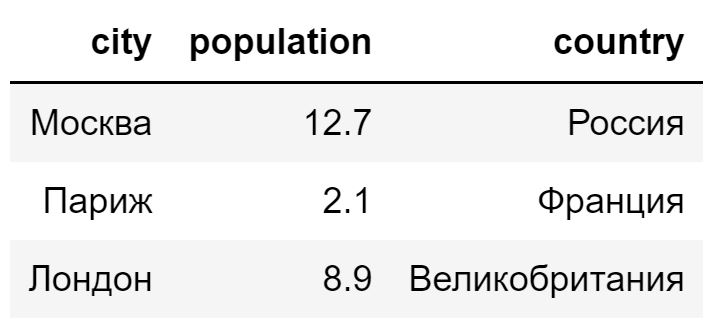
Доступ к элементам датафрейма можно получить по индексам строк и столбцов, которые также начинаются с единицы.
|
1 2 |
# выведем значения первой строки и первого столбца df[1, 1] |

|
1 2 |
# выведем всю первую строку df[1,] |

|
1 2 |
# выведем второй столбец df[,2] |
|
1 |
12.7 2.1 8.9 |
Получить доступ к столбцам можно и так.
|
1 |
df$population |
|
1 |
12.7 2.1 8.9 |
Дополнительные пакеты
Как и в Питоне, в R мы можем установить дополнительные пакеты через Anaconda Prompt. Например, установим пакет ggplot2 для визуализации данных. Для этого введем команду conda install r-ggplot2.
В целом команда установки пакетов для R следующая: conda install r-<package_name>.
Продемонстрируем работу с этим пакетом с помощью несложного датасета mtcars (данные об автомобилях, взятые из журнала Motor Trend за 1974 год).
|
1 2 3 4 5 6 7 8 |
# импортируем библиотеку datasets library(datasets) # загрузим датасет mtcars data(mtcars) # выведем его на экран mtcars |

Теперь импортируем установленную ранее библиотеку ggplot2.
|
1 |
library(ggplot2) |
Построим гистограмму по столбцу mpg (miles per galon, расход в милях на галлон топлива). Для построения гистограммы нам потребуется через «+» объединить две функции:
- функцию ggplot(), которой мы передадим наши данные и еще одну функцию aes(), от англ. aesthetics, которая свяжет ось x нашего графика и столбец данных mpg; а также
- функцию geom_histogram() с параметрами bins (количество интервалов) и binwidth (их ширина), которая и будет отвечать за создание гистограммы.
|
1 2 3 4 5 |
# данными будет датасет mtcars, столбцом по оси x - mpg ggplot(data = mtcars, aes(x = mpg)) + # типом графика будет гистограмма с 10 интервалами шириной 5 миль на галлон каждый geom_histogram(bins = 10, binwidth = 5) |
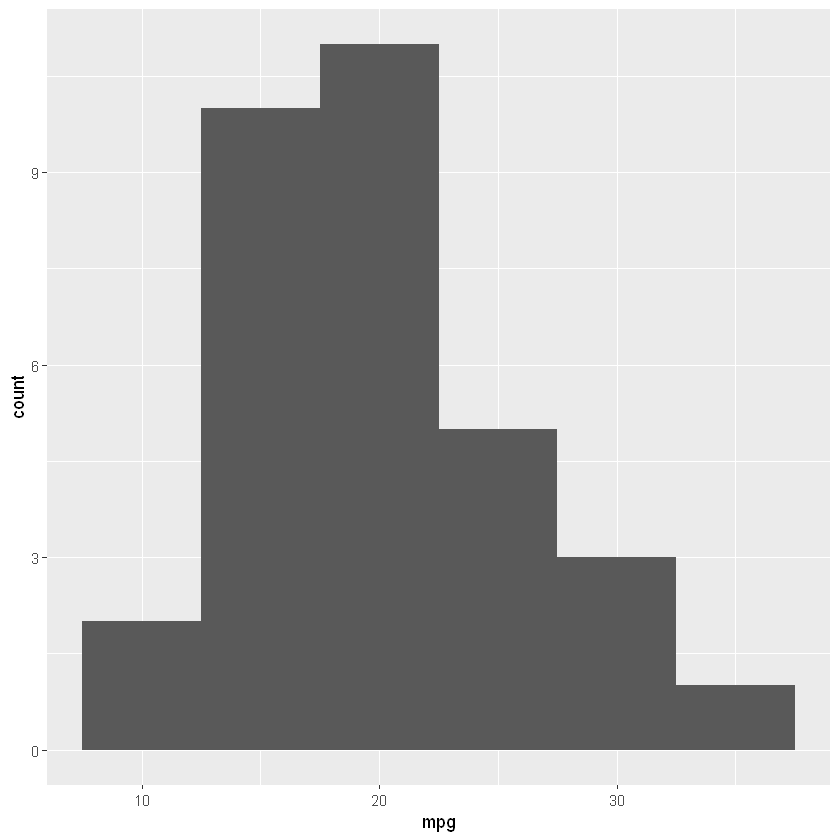
Примерно так же мы можем построить график плотности распределения (density plot). Только теперь мы передадим функции aes() еще один параметр fill = as.factor(vs), который (предварительно превратив столбец в фактор через as.factor()) позволит разбить данные на две категории по столбцу vs. В этом датасете признак vs указывает на конфигурацию двигателя (расположение цилиндров), v-образное, v-shaped (vs == 0) или рядное, straight (vs == 1).
Кроме того, для непосредственного построения графика мы будем использовать новую функцию geom_density() с параметром alpha, отвечающим за прозрачность заполнения пространства под кривыми.
|
1 2 |
ggplot(data = mtcars, aes(x = mpg, fill = as.factor(vs))) + geom_density(alpha = 0.3) |

Дополнительно замечу, что к столбцам датафрейма можно применять множество различных функций, например, рассчитать среднее арифметическое или медиану с помощью несложных для запоминания mean() и median().
|
1 2 |
mean(mtcars$mpg) median(mtcars$mpg) |
|
1 2 |
20.090625 19.2 |
Кроме того, мы можем применить уже знакомую нам функцию summary(), которая для количественного столбца выдаст минимальное и максимальное значения, первый (Q1) и третий (Q3) квартили, а также медиану и среднее значение.
|
1 |
summary(mtcars$mpg) |
|
1 2 |
Min. 1st Qu. Median Mean 3rd Qu. Max. 10.40 15.43 19.20 20.09 22.80 33.90 |
В файле ниже содержится созданный нами код на R.
Вернемся к основной теме занятия.