Все курсы > Вводный курс > Занятие 8
На прошлом занятии мы уже начали работать с данными и статистикой. Сегодня мы продолжим этот путь.
Какая бывает статистика

Иногда данных бывает так много, что чтобы увидеть картину в целом, их нужно обобщить. Этим занимается описательная статистика (Descriptive Statistics).
Причем обобщить правильно, чтобы наши измерения отражали реальное положение вещей. Известное высказывание Марка Твена о том, что «существует три вида лжи: ложь, наглая ложь и статистика», верно лишь в той степени, в которой мы сознательно или по незнанию искажаем сбор и описание данных. Сама статистика здесь ни при чем.
Кроме того, довольно часто нам нужно составить представление о явлении, охватить которое наблюдением мы не можем. Например, мы хотим понять насколько эффективно новое лекарство, но обследовать всех, кто его принял, не представляется возможным. Статистический вывод (Statistical Inference) позволяет сделать обоснованное предположение о явлении в целом по ограниченному числу наблюдений.
На этом занятии мы поговорим про описательную статистику, на следующем — займемся статистическим выводом.
Вначале откроем ноутбук к этому занятию⧉
Начнем с того, что данные (или как еще говорят переменные) бывают двух видов, категориальные и количественные.
1. Категориальные (качественные) данные
Это данные, которые можно отнести к какой-то категории (categorical data). Например, людей можно разделить на мужчин и женщин, на детей и взрослых. Категориями могут быть профессии, группа крови, принадлежность к политической партии. Разделение книг по жанрам или потребителей по степени их удовлетворенности будет категориальной переменной.
Пример: сколько студентов учится на каждом курсе университета
Единицей наших данных в этом примере будут студенты. Категорией будет курс.
Самое простое, что мы можем сделать при работе с такой переменной, это взять наблюдения каждой категории и посчитать их количество. График, который помогает оценить такие данные, называется столбчатой диаграммой (bar chart).
Мы уже знакомы с библиотекой Matplotlib. Ей и воспользуемся.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# импортируем модуль pyplot из библиотеки matplotlib import matplotlib.pyplot as plt # подготовим наши данные # во-первых, возьмем список курсов year = ['Первый', 'Второй', 'Третий', 'Четвертый', 'Пятый'] # во-вторых, количество студентов на каждом из них frequency = [500, 470, 300, 260, 220] # воспользуемся функцией bar() и передадим ей два списка в качестве аргументов plt.bar(year, frequency) # создадим заголовок и подписи к осям, здесь ничего нового plt.xlabel('Курс') plt.ylabel('Количество студентов') plt.title('Распределение студентов по курсам университета') |
Результат:

Какой вывод можно сделать на основе этих данных? До пятого курса доходят не все. Причем больше всего студентов отчисляется после второго курса, руководству вуза стоит обратить внимание именно на этих студентов. Без графика картина была бы не так очевидна.
Теперь про количественные данные.
2. Количественные данные
Примером количественных данных (quantitative data) может быть рост и вес людей, расстояние до объекта, уровень дохода и цена товара. Количественные данные — это всегда какое-то числовое значение, не категория.
Пример: рост мужчин в России
Давайте будем спрашивать у мужчин на улице, какой у них рост и поместим эти данные в питоновский список:
|
1 2 |
# данные по 1000 респондентов в сантиметрах [185.0, 179.0, 186.0, 195.0, 178.0, 178.0, 196.0, 188.0, 175.0, 185.0, 175.0, 175.0, 182.0, 161.0, 163.0, 174.0, 170.0, 183.0, 171.0, 166.0, 195.0, 178.0, 181.0, 166.0, 175.0, 181.0, 168.0, 184.0, 174.0, 177.0, 174.0, 199.0, 180.0, 169.0, 188.0, 168.0, 182.0, 160.0, 167.0, 182.0, 187.0, 182.0, 179.0, 177.0, 165.0, 173.0, 175.0, 191.0, 183.0, 162.0, 183.0, 176.0, 173.0, 186.0, 190.0, 189.0, 172.0, 177.0, 183.0, 190.0, 175.0, 178.0, 169.0, 168.0, 188.0, 194.0, 179.0, 190.0, 184.0, 174.0, 184.0, 195.0, 180.0, 196.0, 154.0, 188.0, 181.0, 177.0, 181.0, 160.0, 178.0, 184.0, 195.0, 175.0, 172.0, 175.0, 189.0, 183.0, 175.0, 185.0, 181.0, 190.0, 173.0, 177.0, 176.0, 165.0, 183.0, 183.0, 180.0, 178.0, 166.0, 176.0, 177.0, 172.0, 178.0, 184.0, 199.0, 182.0, 183.0, 179.0, 161.0, 180.0, 181.0, 205.0, 178.0, 183.0, 180.0, 168.0, 191.0, 188.0, 188.0, 171.0, 194.0, 166.0, 186.0, 202.0, 170.0, 174.0, 181.0, 175.0, 164.0, 181.0, 169.0, 185.0, 171.0, 195.0, 172.0, 177.0, 188.0, 168.0, 182.0, 193.0, 164.0, 182.0, 183.0, 188.0, 168.0, 167.0, 185.0, 183.0, 183.0, 183.0, 173.0, 182.0, 183.0, 173.0, 199.0, 185.0, 168.0, 187.0, 170.0, 188.0, 192.0, 172.0, 190.0, 184.0, 188.0, 199.0, 178.0, 172.0, 171.0, 172.0, 179.0, 183.0, 183.0, 188.0, 180.0, 195.0, 177.0, 207.0, 186.0, 171.0, 169.0, 185.0, 178.0, 187.0, 185.0, 179.0, 172.0, 165.0, 176.0, 189.0, 182.0, 168.0, 182.0, 184.0, 171.0, 182.0, 181.0, 169.0, 184.0, 186.0, 191.0, 191.0, 166.0, 171.0, 185.0, 185.0, 185.0, 219.0, 186.0, 191.0, 190.0, 187.0, 177.0, 188.0, 172.0, 178.0, 175.0, 181.0, 203.0, 161.0, 187.0, 164.0, 175.0, 191.0, 181.0, 169.0, 173.0, 187.0, 173.0, 182.0, 180.0, 173.0, 201.0, 186.0, 160.0, 182.0, 173.0, 189.0, 172.0, 179.0, 185.0, 189.0, 168.0, 177.0, 175.0, 173.0, 198.0, 184.0, 167.0, 189.0, 201.0, 190.0, 165.0, 175.0, 193.0, 173.0, 184.0, 188.0, 171.0, 179.0, 148.0, 170.0, 177.0, 168.0, 196.0, 166.0, 176.0, 181.0, 194.0, 166.0, 192.0, 180.0, 170.0, 185.0, 182.0, 174.0, 181.0, 176.0, 181.0, 187.0, 196.0, 168.0, 201.0, 160.0, 178.0, 186.0, 183.0, 174.0, 178.0, 175.0, 174.0, 188.0, 184.0, 173.0, 189.0, 183.0, 188.0, 186.0, 172.0, 174.0, 187.0, 186.0, 180.0, 181.0, 193.0, 174.0, 185.0, 178.0, 178.0, 191.0, 188.0, 188.0, 193.0, 180.0, 187.0, 177.0, 183.0, 179.0, 181.0, 186.0, 172.0, 201.0, 170.0, 168.0, 192.0, 188.0, 186.0, 186.0, 180.0, 171.0, 181.0, 173.0, 190.0, 179.0, 172.0, 177.0, 184.0, 174.0, 172.0, 182.0, 182.0, 175.0, 175.0, 182.0, 166.0, 166.0, 173.0, 178.0, 183.0, 195.0, 189.0, 178.0, 180.0, 170.0, 180.0, 177.0, 183.0, 172.0, 185.0, 195.0, 179.0, 184.0, 187.0, 176.0, 182.0, 180.0, 181.0, 172.0, 180.0, 185.0, 195.0, 190.0, 202.0, 172.0, 189.0, 182.0, 202.0, 172.0, 172.0, 174.0, 159.0, 175.0, 172.0, 182.0, 183.0, 199.0, 190.0, 174.0, 171.0, 185.0, 167.0, 198.0, 192.0, 175.0, 163.0, 194.0, 179.0, 192.0, 164.0, 174.0, 180.0, 180.0, 175.0, 186.0, 169.0, 179.0, 181.0, 185.0, 187.0, 169.0, 165.0, 193.0, 183.0, 173.0, 196.0, 181.0, 192.0, 181.0, 201.0, 198.0, 178.0, 190.0, 186.0, 194.0, 170.0, 187.0, 191.0, 162.0, 168.0, 160.0, 177.0, 187.0, 195.0, 181.0, 196.0, 166.0, 163.0, 179.0, 184.0, 180.0, 159.0, 179.0, 167.0, 187.0, 184.0, 171.0, 175.0, 169.0, 179.0, 190.0, 170.0, 185.0, 175.0, 172.0, 179.0, 170.0, 174.0, 168.0, 200.0, 180.0, 173.0, 182.0, 179.0, 178.0, 186.0, 188.0, 175.0, 174.0, 177.0, 157.0, 165.0, 194.0, 196.0, 178.0, 186.0, 183.0, 211.0, 191.0, 179.0, 170.0, 164.0, 182.0, 172.0, 166.0, 174.0, 169.0, 197.0, 189.0, 180.0, 195.0, 181.0, 171.0, 195.0, 185.0, 170.0, 178.0, 171.0, 166.0, 189.0, 199.0, 166.0, 186.0, 173.0, 175.0, 174.0, 171.0, 180.0, 172.0, 183.0, 179.0, 178.0, 171.0, 174.0, 188.0, 185.0, 170.0, 181.0, 188.0, 163.0, 185.0, 173.0, 186.0, 172.0, 162.0, 164.0, 180.0, 183.0, 171.0, 186.0, 163.0, 179.0, 168.0, 173.0, 180.0, 171.0, 176.0, 190.0, 174.0, 188.0, 169.0, 185.0, 194.0, 155.0, 172.0, 186.0, 178.0, 184.0, 174.0, 181.0, 178.0, 192.0, 183.0, 183.0, 176.0, 175.0, 176.0, 184.0, 176.0, 183.0, 201.0, 189.0, 177.0, 192.0, 176.0, 160.0, 170.0, 161.0, 176.0, 180.0, 197.0, 183.0, 178.0, 188.0, 158.0, 182.0, 188.0, 165.0, 191.0, 183.0, 176.0, 186.0, 203.0, 182.0, 182.0, 175.0, 172.0, 188.0, 171.0, 181.0, 175.0, 185.0, 183.0, 190.0, 175.0, 177.0, 170.0, 176.0, 184.0, 188.0, 171.0, 189.0, 194.0, 184.0, 199.0, 172.0, 168.0, 162.0, 195.0, 187.0, 179.0, 183.0, 169.0, 204.0, 181.0, 181.0, 187.0, 185.0, 182.0, 172.0, 185.0, 199.0, 193.0, 196.0, 175.0, 170.0, 179.0, 181.0, 191.0, 163.0, 195.0, 178.0, 176.0, 170.0, 163.0, 188.0, 181.0, 167.0, 167.0, 177.0, 197.0, 177.0, 165.0, 178.0, 177.0, 153.0, 179.0, 178.0, 187.0, 198.0, 191.0, 177.0, 169.0, 206.0, 181.0, 180.0, 180.0, 182.0, 179.0, 174.0, 175.0, 180.0, 175.0, 173.0, 181.0, 177.0, 195.0, 153.0, 191.0, 192.0, 159.0, 177.0, 176.0, 166.0, 172.0, 169.0, 198.0, 189.0, 193.0, 187.0, 169.0, 175.0, 185.0, 168.0, 187.0, 178.0, 176.0, 187.0, 184.0, 176.0, 192.0, 169.0, 186.0, 186.0, 177.0, 183.0, 167.0, 189.0, 178.0, 175.0, 190.0, 173.0, 166.0, 164.0, 186.0, 167.0, 198.0, 159.0, 197.0, 182.0, 179.0, 175.0, 184.0, 180.0, 191.0, 181.0, 182.0, 176.0, 179.0, 183.0, 163.0, 167.0, 187.0, 182.0, 178.0, 180.0, 183.0, 175.0, 172.0, 182.0, 170.0, 184.0, 163.0, 190.0, 185.0, 183.0, 190.0, 197.0, 190.0, 162.0, 167.0, 174.0, 180.0, 185.0, 173.0, 182.0, 172.0, 174.0, 166.0, 171.0, 166.0, 170.0, 191.0, 171.0, 206.0, 185.0, 182.0, 171.0, 187.0, 174.0, 181.0, 206.0, 179.0, 191.0, 173.0, 180.0, 198.0, 174.0, 198.0, 187.0, 174.0, 186.0, 190.0, 186.0, 164.0, 173.0, 178.0, 179.0, 186.0, 182.0, 167.0, 184.0, 186.0, 186.0, 191.0, 188.0, 185.0, 179.0, 163.0, 184.0, 182.0, 183.0, 167.0, 169.0, 191.0, 180.0, 187.0, 180.0, 180.0, 189.0, 175.0, 181.0, 175.0, 176.0, 177.0, 182.0, 175.0, 193.0, 171.0, 178.0, 176.0, 194.0, 182.0, 190.0, 165.0, 183.0, 189.0, 181.0, 191.0, 175.0, 194.0, 203.0, 176.0, 176.0, 195.0, 196.0, 175.0, 176.0, 177.0, 167.0, 171.0, 170.0, 172.0, 180.0, 182.0, 196.0, 170.0, 190.0, 178.0, 180.0, 187.0, 169.0, 184.0, 182.0, 185.0, 183.0, 205.0, 174.0, 175.0, 174.0, 174.0, 174.0, 192.0, 194.0, 174.0, 172.0, 185.0, 174.0, 186.0, 182.0, 165.0, 195.0, 198.0, 174.0, 176.0, 183.0, 183.0, 187.0, 200.0, 178.0, 172.0, 166.0, 173.0, 180.0, 198.0, 175.0, 182.0, 180.0, 192.0, 205.0, 175.0, 175.0, 190.0, 187.0, 198.0, 186.0, 176.0, 186.0, 191.0, 188.0, 185.0, 191.0, 192.0, 194.0, 186.0, 178.0, 181.0, 192.0, 172.0, 184.0, 176.0, 180.0, 193.0, 182.0, 180.0, 166.0, 187.0, 186.0, 202.0, 177.0, 182.0, 182.0, 196.0, 179.0, 183.0, 186.0, 182.0, 176.0, 182.0, 191.0, 170.0, 181.0, 173.0, 192.0, 165.0, 174.0, 184.0, 196.0, 179.0, 174.0, 199.0, 166.0, 158.0, 184.0, 175.0, 170.0, 187.0, 182.0, 174.0, 167.0, 189.0, 187.0, 179.0, 198.0, 169.0, 165.0, 173.0, 180.0, 182.0, 178.0, 184.0, 167.0, 194.0, 179.0, 191.0, 183.0, 185.0, 186.0, 184.0, 186.0, 193.0, 182.0, 187.0, 179.0, 194.0, 173.0, 198.0, 180.0, 166.0, 181.0, 173.0, 188.0, 173.0, 176.0, 161.0, 175.0, 156.0, 164.0, 188.0, 188.0, 184.0, 170.0, 180.0, 180.0, 168.0, 195.0, 189.0, 178.0, 180.0, 182.0, 160.0, 178.0, 173.0, 170.0, 177.0, 198.0, 186.0, 174.0, 186.0] |
Теперь для удобства создадим группы или интервалы (bin) роста и посчитаем, сколько людей попадет в каждый из этих интервалов. В этом нам поможет функция hist из той же библиотеки Matplotlib.
|
1 2 3 4 5 6 7 8 9 10 |
# зададим количество интервалов, в которые мы помещали наших респондентов bins = 10 # построим гистограмму plt.hist(height, bins) # создадим заголовок и подписи к осям plt.xlabel('Рост респондентов, см') plt.ylabel('Количество респондентов') plt.title('Распределение роста мужчин в России') |
Количество интервалов можно выбирать произвольно. Обычно останавливаются на том количестве, которое обеспечивает наглядность данных. В нашем случае интервалов будет 10. Ширину интервала Питон подберет сам.
Посмотрим на результат:
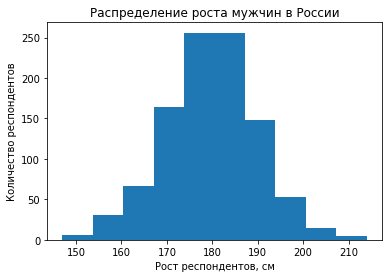
Построенный нами график называется гистограммой (histogram).
Что мы можем сказать по этому графику? Средний рост мужчин вероятно составляет 180 см и довольно мало мужчин ростом ниже 160 см и выше двух метров. Картина выглядит логичной.
Обратите внимание, что столбчатая диаграмма и гистограмма — это два разных графика. Первый нужен для представления категориальных данных, второй — для количественных. Их часто путают.
В то же время, к сожалению, «на глаз» дать более точную оценку нашим данным будет сложно. Нам нужны количественные измерения. Давайте посмотрим, что можно измерить.

Поиск среднего
Первое количественное измерение, которое мы можем провести, это найти среднее.
Среднее арифметическое
С одним из видов средних значений, средним арифметическим, мы уже познакомились на прошлом занятии. Посчитаем его для наших данных.
Напомню, что среднее арифметическое (mean) — это сумма всех значений, поделенная на их количество. Для первых пяти значений среднее арифметическое будет следующим:
$$ \frac {185 + 179 + 186 + 195 + 178}{5} = 184.6 $$
Приведу также и формулу. Постепенно нам нужно будет привыкать ими пользоваться.
$$ \overline{x} = \frac {1}{n} \sum^{n}_{i=1} x_i= \frac {x_1 + x_2 + \dots + x_n}{n} $$
Для 1000 значений посчитать среднее арифметическое вручную сложнее. Воспользуемся Питоном и новым для нас модулем statistics, который вычислит среднее для питоновского списка.
|
1 2 3 4 5 |
# импортируем нужный нам модуль import statistics # посчитаем среднее арифметическое np.round(statistics.mean(height), 2) |
Результат:
|
1 |
180.2 |
Медиана
Медиана (median) — еще одна мера среднего. Рассчитывают ее так: выстраивают все данные от меньшего к большему и берут то значение, которое находится посередине. Вычислим медиану для первых пяти значений. Для этого,
- Проранжируем наши данные по возрастанию: 178, 179, 185, 186, 195
- Медианой будет третий (средний) элемент списка. Этот элемент равен 185 сантиметрам
Чтобы рассчитать медиану для всех значений, снова воспользуемся модулем statistics.
|
1 2 |
# посчитаем медиану statistics.median(height) |
Результат:
|
1 |
180.0 |
Мода
Третьей мерой среднего является мода (mode). Ее рассчитать несложно. Это просто наиболее часто встречающееся значение.
В пяти приведенных значениях моды нет. Все значения разные. При этом, если бы первое значение было равно 179, то именно это значение и стало бы модой. Оно встречалось бы дважды: 179, 179, 185, 186, 195.
Рассчитаем моду для всего набора данных:
|
1 2 |
# посчитаем моду statistics.mode(height) |
Результат:
|
1 |
182.0 |
Зачем столько средних?
Возможно вам стало интересно, зачем столько измерений одного и того же. Дело в том, что иногда выбор типа среднего может очень сильно повлиять на наши выводы.
Допустим, у нас есть пять человек, доход которых (в тысячах рублей) мы поместили в питоновский список и рассчитали среднее арифметическое и медиану:
|
1 2 3 4 5 |
# зарплаты salary = [75, 86, 90, 83, 100] # и их средние показатели print(statistics.mean(salary), statistics.median(salary)) |
Результат:
|
1 |
86.8 86 |
Теперь предположим, что человек, получавший 100 тысяч рублей получил повышение, и теперь зарабатывает 200 тысяч. Означает ли это, что доход всех людей в среднем вырос? Среднее арифметическое и медиана дадут разные ответы на этот вопрос:
|
1 2 |
salary_new = [75, 86, 90, 83, 200] print(statistics.mean(salary_new), statistics.median(salary_new)) |
Результат:
|
1 |
106.8 86 |
Как мы видим, среднее арифметическое выросло очень существенно, медиана осталась прежней. Именно медиана в данном случае дает более адекватную оценку среднего, потому что в действительности доход большинства людей не изменился, и мы не можем говорить, что они стали богаче только потому, что один человек стал получать больший доход.
Обращайте на это внимание, когда будете слышать в новостях о росте средней зарплаты. Очень важно знать каким средним этот рост посчитали.
Разброс или отклонение от среднего
Помимо среднего значения нам было бы интересно узнать насколько данные отклоняются от среднего. Посмотрите на две гистограммы ниже, у них одинаковое среднее (примерно равно нулю) и одинаковое количество наблюдений (по 1000 в каждом), но разве эти графики идентичны? Нет, и виной всему разный разброс данных у variable_a и variable_b. В первом случае разброс от −5 до 5, во втором — от −10 до 10.

На этом занятии мы не будем считать разброс вручную, отложим это знакомство до последующих курсов. Скажу лишь, что наиболее популярной мерой разброса или отклонения от среднего является среднее квадратическое отклонение или СКО (standard deviation).
Для нашей 1000 наблюдений роста мужчин мы рассчитаем СКО с помощью Питона.
|
1 2 |
# рассчитаем СКО с помощью функции stdev, от английского standard deviation statistics.stdev(height) |
Результат.
|
1 |
9.813200186376404 |
Другими словами, рост отклоняется от среднего примерно на 10 см.
Интересный факт, почти все наблюдения укладываются в три стандартных отклонения в обе стороны от среднего. В нашем случае, они находятся в диапазоне от 180 − 3 х 10 и 180 + 3 х 10 или в диапазоне от 150 до 210 см.

Это все, что я хотел вам рассказать сегодня. Надеюсь, было интересно.
Подведем итог
Итак, вы узнали про описательную статистику и статистический вывод.
Кроме этого, вы познакомились с категориальными и количественными данными.
- Для визуализации категориальных данных мы использовали столбчатую диаграмму
- Количественные данные мы:
- Во-первых, представили с помощью гистограммы
- И, во-вторых, смогли описать с помощью точных метрик, средних значений (среднего арифметического, медианы и моды) и разброса (среднеквадратического отклонения)
Вопросы и упражнения для закрепления
Облигациям присваивают рейтинг надежности: высокий, средний и низкий. Это категориальные или количественные данные?
Посмотреть правильный ответ
Ответ: категориальные
Вы записывали показания измерительного прибора (пусть это будет штангенциркуль) и собрали следующие данные: 22, 24, 18, 17, 22 мм. Рассчитайте среднее арифметическое, медиану и моду.
Посмотреть правильный ответ
Ответ: среднее арифметическое 20.6, медиана 22 и мода 22 мм.
Дополнительные упражнения⧉ вы найдете в конце ноутбука.
На следующем занятии мы посмотрим, что такое статистически значимый вывод.
Ответы на вопросы
Вопрос. Почему в расчете среднего арифметического используется код np.round(statistics.mean(height), 2), а при расчетах медианы и моды соответственно statistics.median(height) и statistics.mode(height).
В моем понимании код для вычисления СА должен быть statistics.mean(height)
Ответ. Конечно можно и так, функция np.round() просто округляет значение.