Все курсы > Оптимизация > Занятие 7
В рамках вводного курса мы подробно обсудили вопрос разделения выборки на обучающую и тестовую части, а также затронули проблему переобучения и недообучения модели. Рассмотрим этот вопрос более подробно.
Переобучение и недообучение модели
Переобучение (overfitting) случается, когда модель показывает хороший результат на обучающей выборке и сильно «проседает» на тестовых данных. При недообучении (underfitting) наоборот у алгоритма не получается уловить зависимость на обучающих данных.
Вспомним график из вводного курса.
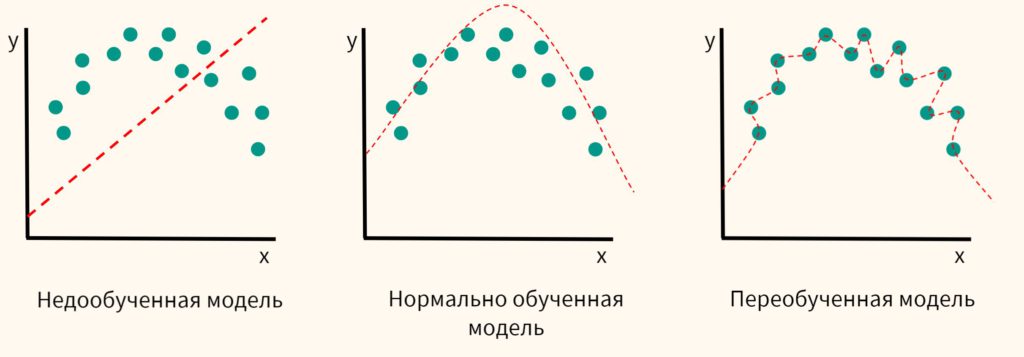
Дополним его для наглядности иллюстрацией того, как может повести себя переобученная модель на тестовых данных.

Также рассмотрим пример переобучения и недообучения в задаче классификации.

С точки зрения уровня ошибки на обучающих и тестовых данных можно привести следующий график. Предположим, что мы взяли полиномиальную регрессию и смотрим на значение функции потерь на обучающих и тестовых данных для различных степеней регрессии.

Как вы видите, после определенной границы сложности модели ошибка на тестовых данных начала расти. Рассмотрим этот вопрос под разными углами и введем несколько новых терминов.
Сложность модели
Причиной пере- и недообучения может быть степень сложности используемой модели (model complexity). Под сложностью в данном случае понимается тип или типы используемых алгоритмов, способность к выявлению линейных или нелинейных зависимостей, количество рассматриваемых признаков и другие факторы.
В целом, можно сказать, что более простая модель склонна к недообучению, более сложная — к переобучению.
Например, полиномиальная модель (особенно с полиномом высокой степени) зачастую способна уловить более сложную зависимость, чем модель линейной регрессии. Если модель хорошо описывает исходные данные, говорят, что у нее низкое смещение.
Смещение
Cмещение (bias) означает матожидание разности между истинным и прогнозным значением.
$$ Bias = E [\hat{y}-y] $$
Другими словами, смещение показывает, насколько хорошо модель обучилась на имеющихся данных (настроилась на выборку). Впрочем, как мы уже сказали в самом начале, идеально обученная (переобученная) модель может иметь минимальное смещение и при этом показать слабые результаты на тестовых данных. В этом случае говорят о большом разбросе.
Разброс
Разброс (variance) показывает насколько результат модели на обучающей выборке отличается от результата модели на тестовой выборке. То есть предсказания на тесте (например, на нескольких выборках) имеют разброс, и нам важно чтобы эти результаты не слишком отличались (тогда можно сказать, что у модели хорошая обобщающая способность).
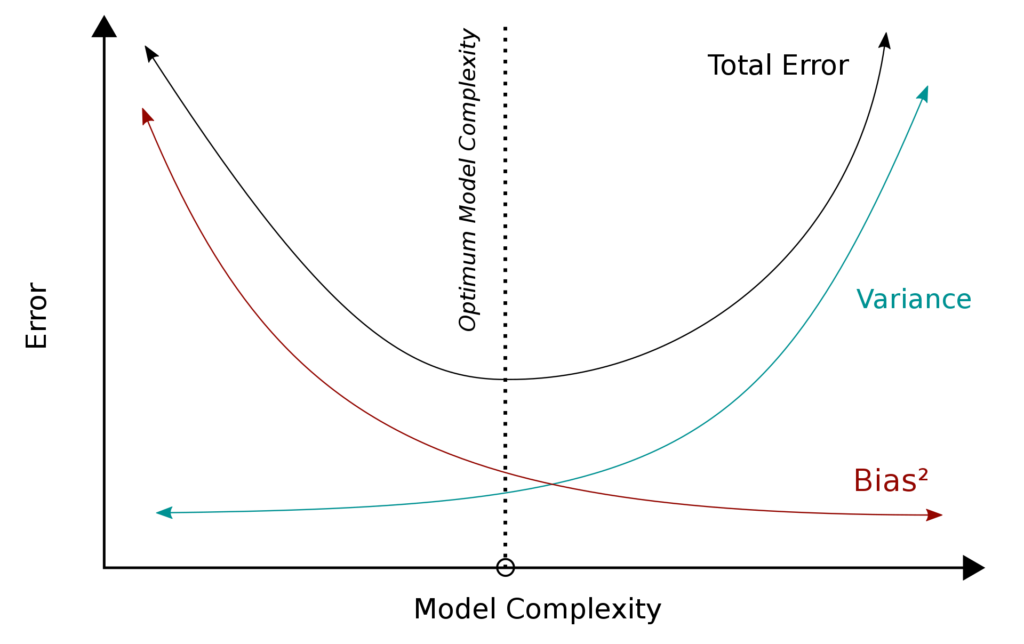
Компромисс смещения и разброса
На практике стремление к снижению смещения может привести к увеличению разброса, т.е. переобучению, и, наоборот, высокое смещение модели может способствовать низкому разбросу, но смысла в этом не будет, потому что модель будет недообучена.
Эту проблему принято называть компромиссом или дилеммой смещения и разброса (bias-variance tradeoff). Посмотрим на рисунок ниже.
Рассмотрим еще одну полезную для понимания смещения и разброса иллюстрацию. На левом графике изобразим модели (каждая точка на графике — это прогноз одной модели), которые не очень хорошо описывают данные. Например, представим, что мы пытаемся описать полиномом первой степени зависимость, которая гораздо лучше описывается с помощью квадратичной функции.
Оценим прогнозы этих моделей в условной точке x = 5.

Коричневым цветом обозначены те «правильные» ответы, которые мы хотели бы получить. Свести их в одну точку мы не можем, потому что даже в идеальном случае мы можем получить прогноз с точностью до шума (случайных колебаний). Bias (фиолетовая стрелка) отражает ошибку, связанную с тем, что мы ошиблись с выбором модели (степень полинома). Разброс (зеленый цвет) — прогнозы моделей на нескольких обучающих выборках.
На правом графике, благодаря правильно подобранным (например, полином второй степени, снижает bias) и хорошо настроенным (снижает variance) моделям мы смогли существенно улучшить качество ответов.
Математика
Выразим три упомянутых компонента (смещение, разброс/дисперсия, шум) математически. Изначально мы хотим предсказать следующую зависимость.
$$ \hat{f}(X) = f(X) + \varepsilon, \varepsilon \sim N(0, \sigma_{\varepsilon}) $$
Ошибка в точке x равна
$$ Err(x) = E[(Y-\hat{f}(x))^2] $$
Ошибку можно разложить на
$$ Err(x) = \left( E[\hat{f}(x)]-f(x) \right)^2 + E \left[ \left( \hat{f}(x)-E[\hat{f}(x)] \right)^2 \right] + \sigma^2_{\varepsilon} $$
Что представляет собой
$$ Err(x) = Bias^2 + Variance + Noise $$
В случае дисперсии мы находим матожидание прогнозных значений различных моделей $E[\hat{f}(x)]$, вычитаем его из прогнозов моделей $\hat{f}(x)$, возводим в квадрат и находим матожидание отклонений.
Приведем разложение (здесь полезно вспомнить, что дисперсия равна матожиданию квадрата минус квадрат матожидания). Для простоты обозначим истинные значения как $y,$ прогнозные как $\hat{y}$.
$$ E(y-\hat{y})^2 = E(y^2 + \hat{y}^2-2y\hat{y}) = $$
$$ E(y^2)-(Ey)^2+(Ey)^2 + $$
$$ E(\hat{y}^2)-(E\hat{y})^2+(E\hat{y})^2-2(Ey\hat{y}) = $$
$$ Dy + D\hat{y} + (Ey)^2 +(E\hat{y})^2-2(Ey\hat{y}) = $$
$$ Dy + D\hat{y} + E(y-\hat{y})^2 $$
Как бороться с переобучением?
Сложная, переобученная модель может иметь очень много признаков (особенно если речь идёт о полиноме).
Очевидно, в большинстве случае визуальный подбор степени полинома (как мы это делали ранее для линейной и логистической полиномиальных регрессий) не представляется возможным. Более того, модели с таким количеством признаков в силу их высокой сложности (complexity) склонны к переобучению.
Бороться с этим можно тремя способами:
Первый вариант. Увеличить размер обучающей выборки. Маленькая выборка снижает обобщающую способность модели, а значит повышает разброс.
Второй вариант. Уменьшить количество признаков (вручную или через алгоритм, кроме того вводить наказание за новые признаки, как например, скорректированный коэффициент детерминации, adjusted R-square). Опасность здесь — выбросить нужные признаки.
Третий вариант. Использовать регуляризацию, которая позволяет снижать параметр (вес, коэффициент) признака и, таким образом, снижать его значимость. Предположим, что мы хотим уменьшить влияние второго признака в модели ниже.
$$ y = 15x_1 + 10x_2 + 5 \rightarrow y = 15x_1 + 5x_2 + 5 $$
Подобное изменение, как правило, приводит к тому, что модель меньше настраивается на шум (излишнюю вариативность) в обучающих данных и, как следствие, показывает лучшие результаты на тестовой выборке.
Другими словами, по сравнению с обычной линейной регрессией, у нее немного большее смещение (bias), но зато заметно меньший разброс (variance).
Три дополнительных соображения:
- Очевидно, что если мы снизим параметр признака до нуля, то этот признак будет удален из модели.
- Как правило, не имеет смысла применять регуляризацию к свободному коэффициенту $ \theta_0 $.
- Очень маленькие значения $\theta$ также могут повышать ошибку
Откроем ноутбук к этому занятию⧉
Регуляризация линейной регрессии
Рассмотрим несколько вариантов регуляризации линейной регрессии: Ridge, Lasso и Elastic Net.
Подготовка данных
Подгрузим данные о недвижимости в Бостоне, разделим на обучающую и тестовую части и выполним стандартизацию.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
boston = pd.read_csv('/content/boston.csv') X = boston[['LSTAT', 'RM', 'PTRATIO', 'INDUS']] y = boston.MEDV from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 42) from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test) |
Ordinary Least Squares
Построим регрессию без регуляризации методом наименьших квадратов и выведем RMSE на обучающей и тестовой выборках.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
from sklearn.linear_model import LinearRegression ols = LinearRegression() ols.fit(X_train, y_train) y_pred_train = ols.predict(X_train) y_pred_test = ols.predict(X_test) from sklearn.metrics import mean_squared_error print('train: ' + str(mean_squared_error(y_train, y_pred_train, squared = False))) print('test: ' + str(mean_squared_error(y_test, y_pred_test, squared = False))) |
|
1 2 |
train: 5.255700309296848 test: 5.127682560624116 |
Ridge Regression
Функция потерь
Ридж-регрессия (ridge regression, гребневая регрессия) вводит наказание (penalty) за слишком большие коэффициенты. Это наказание представляет собой сумму коэффициентов $ \theta $, возведенных в квадрат (чтобы положительные и отрицательные значения не взаимоудалялись).
$$ J_{Ridge}(\theta) = MSE + \sum{\theta_i^2} $$
Опять же $\theta_0$ здесь не учитывается. В векторизованной форме,
$$ J_{Ridge}(\theta) = MSE + \theta^T \theta $$
Корень из скалярного произведения вектора на самого себя есть его длина. Так как в данном случае мы корень не извлекаем, то можем записать слагаемое регуляризации (regularization term) как
$$ J_{Ridge}(\theta) = MSE + || \theta ||^2_2 $$
Наконец, введем еще одно дополнение, параметр $\lambda$, который позволит нам контролировать силу воздействия этого слагаемого на уровень ошибки.
$$ J_{Ridge}(\theta) = MSE + \alpha \cdot || \theta ||^2_2 $$
Замечу также, что Ridge Regression также называют L2-регуляризацией, потому что она использует L2-норму в качестве соответствующего слагаемого. Посмотрим на иллюстрацию регуляризации.

При регуляризации у нас появляется, по сути, две функции ошибки: основная (синяя), наказывающая за отклонение истинных значений от прогнозных. и дополнительная (оранжевая), наказывающая за отклонение коэффициентов от нуля. Их сумму и будет пытаться минимизировать алгоритм.
Источник картинки и подробности здесь⧉.
Нормальные уравнения
Вспомним аналитическое решение задачи линейной регрессии.
$$ \theta = (X^TX)^{-1}X^Ty $$
В случае нормальных уравнений с L2-регуляризацией оптимальное решение можно найти через
$$ \theta = (X^TX + \alpha I)^{-1}X^Ty $$
$I$ представляет собой единичную матрицу размером $ (j+1) \times (j+1) $ с нулевым значением первого столбца первой строки (сдвиг), где $j$ — количество признаков.
Что интересно, регуляризация решает проблему вырожденных или необратимых матриц. Матрица будет вырожденной в случае, если количество признаков больше количества объектов и может быть необратима, если оно равно количеству объектов. Выражение $X^TX + \alpha I $ решает эту проблему.
Напишем собственный класс.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
class RidgeReg(): def __init__(self, alpha = 1.0): self.alpha = alpha self.thetas = None def fit(self, x, y): x = x.copy() x = self.add_ones(x) I = np.identity(x.shape[1]) I[0][0] = 0 self.thetas = np.linalg.inv(x.T.dot(x) + self.alpha * I).dot(x.T).dot(y) def predict(self, x): x = x.copy() x = self.add_ones(x) return np.dot(x, self.thetas) def add_ones(self, x): return np.c_[np.ones((len(x), 1)), x] |
|
1 2 3 4 5 6 7 8 9 |
ridge = RidgeReg(alpha = 10) ridge.fit(X_train, y_train) y_pred_train = ridge.predict(X_train) y_pred_test = ridge.predict(X_test) print('train: ' + str(mean_squared_error(y_train, y_pred_train, squared = False))) print('test: ' + str(mean_squared_error(y_test, y_pred_test, squared = False))) |
|
1 2 |
train: 5.258077962476522 test: 5.104623428412015 |
Ошибка на обучающей выборке немного выросла, на тесте немного уменьшилась. Сравним с sklearn.
|
1 2 3 4 5 6 7 8 9 10 11 |
from sklearn.linear_model import Ridge ridge = Ridge(alpha = 10) ridge.fit(X_train, y_train) y_pred_train = ridge.predict(X_train) y_pred_test = ridge.predict(X_test) print('train: ' + str(mean_squared_error(y_train, y_pred_train, squared = False))) print('test: ' + str(mean_squared_error(y_test, y_pred_test, squared = False))) |
|
1 2 |
train: 5.258077962476521 test: 5.104623428412015 |
Выведем изменение коэффициентов на графике.
|
1 2 3 4 5 6 7 8 |
features = X.columns plt.figure(figsize = (5, 5)) plt.plot(features, ridge.coef_, alpha=0.7, linestyle='none' , marker='*', markersize=5, color='red', label=r'Ridge; $\alpha = 10$', zorder = 7) plt.plot(features, ols.coef_, alpha=0.4, linestyle='none', marker='o', markersize=7, color='green',label='Linear Regression') plt.xticks(rotation = 0) plt.legend() plt.show() |

Метод градиентного спуска
Эту же задачу можно решить методом градиентного спуска. Функция потерь в этом случае будет иметь вид
$$ J({\theta_j}) = \frac{1}{2n} \sum (y-\theta X)^2 + \frac{1}{2n} \lambda \theta^T \theta $$
Для градиентного спуска, чтобы не запутаться, обозначим коэффициент скорости обучения через $\alpha$, а параметр регуляризации через $\lambda$. При этом градиент будет равен
$$ \frac{\partial}{\partial \theta_j} J(\theta) = \left( -x_j(y-X\theta) + \lambda \theta \right) \times \frac{1}{n} $$
Нормализовывать сдвиг не обязательно (в первую очередь имеют значения наклоны). Здесь мы это делаем, чтобы упростить код. Перейдем к практике. Начнем с собственного класса.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
class RidgeGD(): def __init__(self, alpha = 0.0001): self.thetas = None self.loss_history = [] self.alpha = alpha def add_ones(self, x): return np.c_[np.ones((len(x), 1)), x] def objective(self, x, y, thetas, n): return (np.sum((y - self.h(x, thetas)) ** 2) + self.alpha * np.dot(thetas, thetas)) / (2 * n) def h(self, x, thetas): return np.dot(x, thetas) def gradient(self, x, y, thetas, n): return (np.dot(-x.T, (y - self.h(x, thetas))) + (self.alpha * thetas)) / n def fit(self, x, y, iter = 20000, learning_rate = 0.05): x, y = x.copy(), y.copy() x = self.add_ones(x) thetas, n = np.zeros(x.shape[1]), x.shape[0] loss_history = [] for i in range(iter): loss_history.append(self.objective(x, y, thetas, n)) grad = self.gradient(x, y, thetas, n) thetas -= learning_rate * grad self.thetas = thetas self.loss_history = loss_history def predict(self, x): x = x.copy() x = self.add_ones(x) return np.dot(x, self.thetas) |
|
1 2 3 4 5 6 7 8 9 |
ridge_gd = RidgeGD(alpha = 0.0001) ridge_gd.fit(X_train, y_train, iter = 50000, learning_rate = 0.01) y_pred_train = ridge_gd.predict(X_train) y_pred_test = ridge_gd.predict(X_test) print('train: ' + str(mean_squared_error(y_train, y_pred_train, squared = False))) print('test: ' + str(mean_squared_error(y_test, y_pred_test, squared = False))) |
|
1 2 |
train: 5.255700309301131 test: 5.127682311863072 |
Сравним с sklearn. Для того чтобы оптимизировать Ridge регрессию методом градиентного спуска, используем класс SGDRegressor с параметром penalty = ‘l2’. Кроме того, укажем другие параметры для того, чтобы применяемый алгоритм был максимально близок к написанному вручную.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
from sklearn.linear_model import SGDRegressor ridge_gd = SGDRegressor(loss = 'squared_error', penalty = 'l2', alpha = 0.0001, max_iter = 50000, learning_rate = 'constant', eta0 = 0.001, random_state = 42) ridge_gd.fit(X_train, y_train) y_pred_train = ridge_gd.predict(X_train) y_pred_test = ridge_gd.predict(X_test) print('train: ' + str(mean_squared_error(y_train, y_pred_train, squared = False))) print('test: ' + str(mean_squared_error(y_test, y_pred_test, squared = False))) |
|
1 2 |
train: 5.25595467395471 test: 5.120506389637218 |
Выбор $\alpha$
Подобрать оптимальный гиперпараметр регуляризации можно, в частности, с помощью класса RidgeCV, который одновременно выполним оценку качества модели с помощью перекрестной валидации.
Приведем пример.
|
1 2 3 4 5 6 7 8 9 10 |
from sklearn.linear_model import RidgeCV # укажем параметры регуляризации alpha, которые хотим протестировать # дополнительно укажем количество частей (folds), параметр cv, # на которое нужно разбить данные при оценке качества модели ridge_cv = RidgeCV(alphas = [0.1, 1.0, 10], cv = 10) ridge_cv.fit(X_train, y_train) # выведем оптимальный параметр и достигнутое качество ridge_cv.alpha_, ridge_cv.best_score_ |
|
1 |
(10.0, 0.6482859868459572) |
Lasso Regression
Регрессия Lasso для регуляризации использует сумму весов по модулю, то есть L1-норму.
Сравнение L1 и L2 регуляризации
$$ J_{Lasso}(\theta) = MSE + \alpha \cdot || \theta ||_1 $$
Отличие заключается в том, что Ridge-регрессия при возведении $\theta$ в квадрат сильнее «наказывает» за большие коэффициенты, Lasso «наказывает» все коэффициенты одинаково. Например, если $\theta$ равен $ \begin{bmatrix} 10 \\ 5 \end{bmatrix} $, то в первом случае L2-регрессии penalty составит $ 10^2 + 5^2 = 125 $, в случае L1, только 15. При увеличении первого коэффициента на единицу L2-penalty составит $ 11^2 + 5^2 = 146 $, L1 увеличится до 16.
Одновременно этот пример показывает особую важность масштабирования признаков при использовании алгоритма с регуляризацией.
Обнуление коэффициентов
L1 регуляризация может полностью обнулить часть коэффициентов и, таким образом, исключить соответствующие признаки из модели. Эта особенность Lasso регрессии называется parameter sparcity.
Математика
Вначале рассмотрим модель с L2-регуляризацией с одним признаком и одним коэффициентом $\theta$.
$$ L_2 = (y-x\theta)^2+\alpha\theta^2 = y^2-2xy\theta+x^2\theta^2+\alpha\theta^2 $$
Найдем производную относительно $\theta$, приравняем ее к нулю и решим для $\theta$.
$$ \frac{\partial L_2}{\partial \theta} = -2xy + 2x^2\theta + 2\alpha\theta $$
$$ -2xy + 2x^2\theta + 2\alpha\theta = 0 $$
$$ \theta(x^2 + \alpha ) = xy $$
$$ \theta = \frac{xy}{(x^2 + \alpha)} $$
Коэффициент $\theta$ превратится в ноль для ненулевых значений x и y при $\alpha \rightarrow \inf$. Сравним с L1-регуляризацией. Найдем производную относительно $\theta,$ приравняем к нулю и решим для $\theta$ для случаев $\theta > 0$ (в точке ноль производная функции не определена).
$$ \frac{\partial L_1}{\partial \theta} = -2xy + 2x^2\theta + \alpha $$
$$ -2xy + 2x^2\theta + \alpha = 0 $$
$$ 2x^2\theta = 2xy-\alpha $$
$$ \theta = \frac{2xy-\alpha}{2x^2} $$
Сдалаем то же самое для случая, когда $\theta < 0$.
$$ \frac{\partial L_1}{\partial \theta} = -2xy + 2x^2\theta-\alpha $$
$$ -2xy + 2x^2\theta-\alpha = 0 $$
$$ 2x^2\theta = (\alpha + 2xy) $$
$$ \theta = \frac{\alpha + 2xy}{2x^2} $$
В обоих случаях при определенных x, y и $\alpha$ параметр $\theta$ может быть равен нулю.
Дополнительно сравним L2 и L1 нормы двух векторов $ \begin{bmatrix} 1 \\ 0 \end{bmatrix} $ и $ \begin{bmatrix} \frac{1}{\sqrt{2}} \\ \frac{1}{\sqrt{2}} \end{bmatrix} $.
В случае L2-нормы, их длина будет равна единице. В случае L1-нормы длина первого вектора будет равна единце, а второго $\sqrt{2} \approx 1,41$. Таким образом, L1 регуляризация не только допускает, но и способствует обнулению коэффициентов.
Визуализация
Приведем классическую визуализацию границ двух видов регуляризации из книги T. Hastie The Elements of Statistical Learning⧉ (страница 71).

Изолинии отображают уровни ошибки при определенных параметрах $\theta$. Синий ромб и круг задают соответственно границу L1 и L2 регуляризации.
Координатный спуск
Как уже было замечено, производная функции абсолютной величины не определена в точке $x = 0$ и, как следствие, мы не можем использовать обычный алгоритм градиентного спуска.
При этом мы можем двигаться вниз на каждой итерации лишь вдоль одной из координат и остановиться, если этот шаг окажется меньше, чем некоторое заданное нами пороговое значение. Такой метод называется методом координатного спуска (coordinate descent).
Приведем иллюстрацию из Википедии⧉.

Выбрать, по какой координате спускаться можно разными способами, в частности, можно:
- выбирать признак (координату) случайным образом или
- просто идти от признака 0 до j (далее признаки мы будем обозначать так)
Рассмотрим как координатный спуск выглядит с точки зрения математики.
Математика
Итак, напомню, функция потерь будет иметь вид
$$ J_{Lasso}(\theta) = MSE + \alpha \cdot || \theta ||_1 $$
Вначале обратимся к первому компоненту, а именно MSE. Вспомним, чему равен градиент MSE.
$$ \frac{\partial J}{\partial \theta_j} = \frac{1}{n} \times -x_j(y-X\theta) $$
Перепишем $y-X\theta$ как $y-(\theta_kX_k+\theta_jx_j)$.
$$ \frac{1}{n} \times -x_j(y-(\theta_kX_k+\theta_jx_j)) $$
Другими словами, выделим ту координату j (признак), по которой мы будем спускаться в этот раз. $\theta_kX_k$ — это прогноз модели без коордианты j. Раскроем, а затем реорганизуем скобки.
$$ \frac{1}{n} \times -x_j((y-\theta_kX_k)-\theta_jx_j)$$
Умножим $-x_j$ на каждое из слагаемых.
$$ \frac{1}{n} \times -x_j((y-\theta_kX_k) + \theta_j x_j^2 $$
Обозначим компоненты через новые переменные $\rho$ («ро») и $z$.
$$ \rho_j = x_j((y-\theta_kX_k) $$
Примечание. Минус перед $x_j$ появится в окончательной формуле ниже.
$$ z_j = x_j^2 $$
Переменная $\rho$ по сути показывает насколько признак $x_j$ коррелирует с остатками модели $y-\theta_kX_k$, построенной без j. Если $\rho$ (т.е. корреляция) растет, значит этот признак важен для модели и его вес стоит увеличить.
Тогда выражение будет иметь вид
$$ \frac{\partial L}{\partial \theta_j} = -\frac{1}{n}\rho_j + \frac{1}{n} \theta_jz_j $$
Приравняв производную к нулю, найдем решение относительно $\theta_j$.
$$ \theta_j = \frac{\rho_j}{z_j} $$
Замечу, что $z_j$, то есть скалярное произведение вектора признака $x_j$ самого на себя, будет равно единице, если признаки будут предварительно нормализованы (приведены к единичной L2 норме).
Обратимся ко второму компоненту, слагаемому регуляризации. Так как производная в точке $|\theta_j| = 0$ не определена, воспользуемся таким понятием как субградиент (subgradient). По сути, субградиентом является множество возможных градиентов в определенной точке. Приведем иллюстрацию для субградиентов в точке $|\theta_j| = 0$.

Как видно, субградиенты могут принимать значения $[-1, 1]$ (градиенты функции абсолютного значения) или вернее от $[-\alpha, \alpha]$, то есть параметра, на который мы умножаем слагаемое регуляризации.
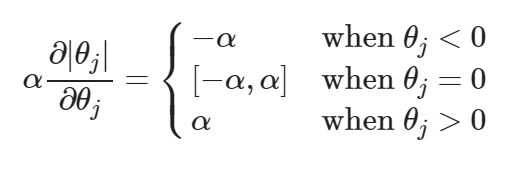
Объединим две производных.

Рассмотрим каждый из трех случаев по отдельности.
Вариант 1. $\theta_j < 0$
$$ -\frac{1}{n}\rho_j + \frac{1}{n} \theta_jz_j-\alpha = 0 $$
$$ \theta_j = \frac{\rho_j + n\alpha}{z_j} $$
Для того чтобы $\theta_j < 0$, необходимо чтобы $\rho_j < n\alpha $
Вариант 2. $\theta_j = 0$
$$ -\frac{1}{n}\rho_j + \frac{1}{n} \theta_jz_j + [-\alpha, \alpha] = 0 $$
$$ \theta_j = \left[ \frac{\rho_j-n\alpha}{z_j}, \frac{\rho_j + n\alpha}{z_j} \right] $$
Для того чтобы $ \theta_j = 0 $, $ -n\alpha\ \leq \rho_j \leq n\alpha $.
Вариант 3. $\theta_j > 0$
$$ -\frac{1}{n}\rho_j + \frac{1}{n} \theta_jz_j + \alpha = 0 $$
$$ \theta_j = \frac{\rho_j-n\alpha}{z_j} $$
Для того чтобы $\theta_j > 0$, $\rho_j > n\alpha $
Сдвиг $\theta_0$ не регуляризуется и изменяется с помощью частной производной MSE (первое слагаемое).
$$ \theta_0 = \frac{\rho_0}{z_0} $$
Таким образом, шаги алгоритма координатного спуска будут следующими:
Шаг 1. Добавить первый (!) столбец из единиц для коэффициента $\theta_0$. Инициализировать веса $\theta$.
Шаг 2. Рассчитать $z_j$.
$$ z_j = \sum x_j^2 $$
Шаг 3. Задать начальный максимальный размер шага (max_step) и пороговое значение (tolerance)
Шаг 4. Пока максимальный размер шага больше порогового значения проходиться в цикле по каждой из координат (признаку), рассчитать $ \rho_j = \sum x_j((y-\theta_kX_k) $ и обновлять вес $\theta$ этого признака в соответствии со следующими правилами:
Если j = 0, то есть первого по счету коэффициента $\theta_0$, то $\theta_j = \frac{ρ_j}{z_j}$.
В остальных случаях
$$ \theta_j = \left\{ \begin{matrix} \frac{\rho_j + n \alpha}{z_j} & if & \rho_j < -n \alpha \\ 0 & if & -n \alpha ≤ \rho_j ≤ n \alpha \\ \frac{\rho_j-n \alpha}{z_j} & if & \rho_j > n \alpha \end{matrix} \right. $$
Обратите внимание, если $ -n\alpha\ \leq \rho_j \leq n\alpha $ (то есть корреляция признака очень мала по модулю), то коэффициент будет обнулен и исключен из модели. В двух других случаях (варианты 1 и 3), мы будем увеличивать коэффициент при большом отрицательном $\rho_j$ и уменьшать при большом положительном (т.е. выполнять регуляризацию). Посмотрим на график ниже.

Такое ограничение называется мягким порогом (soft thresholding). Приведем для сравнения Ridge регрессию, которая сокращает коэффициенты на всем диапазоне $\theta$, но не приводит их к нулевым значениям.
Реализация на Питоне
Объявим вспомогательные функции.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# добавим столбец из единиц в матрицу признаков def add_ones(x): return np.c_[np.ones((len(x), 1)), x] # объявим функцию гипотезы def h(x, theta): # 506 х (4 + 1) на (4 + 1) х 1 return np.matmul(x, theta) # 506 x 1 # рассчитаем rho_j def rho(y, x, theta, j): # удалим признак (координату) j из матрицы признаков и вектора весов x_k = np.delete(x, j, 1) theta_k = np.delete(theta ,j) # сделаем прогноз без j y_pred_k = h(x_k, theta_k) # найдем остатки при прогнозе без j residuals_k = y - y_pred_k # вычислим rho_j rho_j = np.sum(x[:,j] * residuals_k) return rho_j # рассчитаем z def compute_z(x): # рассчитаем z (т.е. L2 норму) для каждого столбца (axis = 0) z_vector = np.sum(x * x, axis = 0) return z_vector |
Объявим функцию координатного спуска.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
def coordinate_descent(x, y, alpha = 0.1, tolerance = 0.0001): x = add_ones(x) theta = np.zeros(x.shape[1], dtype = float) z = compute_z(x) max_step = 100. iterations = 0 # tolerance - пороговое значение, если шаг меньше, остановимся while(max_step > tolerance): iterations += 1 old_theta = np.copy(theta) # поочередно выберем каждый из признаков for j in range(len(theta)): # рассчитаем rho_j rho_j = rho(y, x, theta, j) # пропишем обновление для сдвига (первый по счету коэффициент) if j == 0: theta[j] = rho_j / z[j] # пропишем обновления для остальных признаков elif rho_j < -alpha * len(y): theta[j] = (rho_j + (alpha * len(y))) / z[j] elif rho_j > -alpha * len(y) and rho_j < alpha * len(y): theta[j] = 0. elif rho_j > alpha * len(y): theta[j] = (rho_j - (alpha*len(y))) / z[j] # запишем текущий максимальный для всех координат (!!!) размер шага # (обратите внимание, код ниже выполняется после цикла for) step_sizes = abs(old_theta - theta) max_step = step_sizes.max() return theta, iterations, max_step |
Протестируем алгоритм.
|
1 2 3 4 5 6 7 8 9 |
theta_opt, iterations, max_step = coordinate_descent(X_train, y_train, alpha = 0.2, tolerance = 0.0001) np.set_printoptions(precision = 3, suppress = True) print("Intercept is:",theta_opt[0]) print("\nCoefficients are:\n",theta_opt[1:]) print("\nNumber of iterations is:", iterations) |
|
1 2 3 4 5 6 |
Intercept is: 23.01581920903955 Coefficients are: [-4.228 3.107 -1.811 0. ] Number of iterations is: 11 |
Мы видим, что модель сочла признак INDUS не имеющим значения для данной модели и обнулила соответствующий коэффициент. Сравним с классом Lasso библиотеки sklearn.
|
1 2 3 4 5 6 7 |
from sklearn.linear_model import Lasso lasso = Lasso(alpha = 0.2, tol = 0.0001) lasso.fit(X_train, y_train) print("sklearn Lasso intercept :",lasso.intercept_) print("\nsklearn Lasso coefficients :\n",lasso.coef_) print("\nsklearn Lasso number of iterations :",lasso.n_iter_) |
|
1 2 3 4 5 6 |
sklearn Lasso intercept : 23.01581920903955 sklearn Lasso coefficients : [-4.228 3.107 -1.811 0. ] sklearn Lasso number of iterations : 10 |
Elastic Net Regression
Регрессия Elastic Net использует как L1, так и L2 регуляризацию.
$$ J_{ElasticNet}(\theta) = MSE + \alpha_1 \cdot || \theta ||_1 + \alpha_2 \cdot || \theta ||_2^2 $$
Так как в этой модели есть компонент L-1, для которого в точке $|\theta_j| = 0$ производная не определена, используем один из возможных субградиентов, а именно нулевой субградиент (красная пунктирная линия $g_3$ на рисунке выше).
Другими словами, субградиент для компонента будет выглядеть следующим образом
$$ \frac{\partial J_{L1}}{\partial_{sub} \theta} = \left\{ \begin{matrix} 1 & if & \theta > 0 \\ 0 & if & \theta = 0 \\ -1 & if & \theta < 0 \end{matrix} \right. $$
Это условие соответствует сигнум-функции или функции знака (sign function⧉). На Питоне можно использовать np.sign().
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
class ElasticNet(): def __init__(self, a1 = 0.1, a2 = 0.1): self.thetas = None self.loss_history = [] self.a1 = a1 self.a2 = a2 def add_ones(self, x): return np.c_[np.ones((len(x), 1)), x] def objective(self, x, y, thetas, n): return (np.sum((y - self.h(x, thetas)) ** 2) + self.a1 * np.sum(np.abs(thetas)) + self.a2 * np.dot(thetas, thetas)) / (2 * n) def h(self, x, thetas): return np.dot(x, thetas) def gradient(self, x, y, thetas, n): return (np.dot(-x.T, (y - self.h(x, thetas))) + (self.a1 * np.sign(thetas)) + (self.a2 * thetas)) / n def fit(self, x, y, iter = 20000, learning_rate = 0.05): x, y = x.copy(), y.copy() x = self.add_ones(x) thetas, n = np.zeros(x.shape[1]), x.shape[0] loss_history = [] for i in range(iter): loss_history.append(self.objective(x, y, thetas, n)) grad = self.gradient(x, y, thetas, n) thetas -= learning_rate * grad self.thetas = thetas self.loss_history = loss_history def predict(self, x): x = x.copy() x = self.add_ones(x) return np.dot(x, self.thetas) |
|
1 2 3 4 5 6 7 8 9 |
elastic = ElasticNet() elastic.fit(X_train, y_train, iter = 50000, learning_rate = 0.01) y_pred_train = elastic.predict(X_train) y_pred_test = elastic.predict(X_test) print('train: ' + str(mean_squared_error(y_train, y_pred_train, squared = False))) print('test: ' + str(mean_squared_error(y_test, y_pred_test, squared = False))) |
|
1 2 |
train: 5.255705191138267 test: 5.127348870379186 |
|
1 |
elastic.thetas |
|
1 |
array([23.009, -4.473, 3.219, -1.998, 0.317]) |
Сравним с классом ElasticNet библиотеки sklearn.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
from sklearn.linear_model import ElasticNet elastic = ElasticNet(alpha = 0.05) elastic.fit(X_train, y_train) elastic.fit(X_train, y_train) y_pred_train = elastic.predict(X_train) y_pred_test = elastic.predict(X_test) print('train: ' + str(mean_squared_error(y_train, y_pred_train, squared = False))) print('test: ' + str(mean_squared_error(y_test, y_pred_test, squared = False))) |
|
1 2 |
train: 5.259317264886122 test: 5.100827371724984 |
|
1 |
elastic.intercept_, elastic.coef_ |
|
1 |
(23.01581920903955, array([-4.287, 3.179, -1.944, 0.146])) |
Замечу, что класс ElasticNet библиотеки sklearn использует координатный спуск для минимизации функции потерь. Кроме того, в документации можно посмотреть, как единственный параметр $\alpha$ регулирует значимость L1 и L2 компонентов.
Регуляризация нейросети
В качестве иллюстрации приведем примеры L2 регуляризации нейронной сети.
Функция потерь с регуляризацией
Посмотрим на функцию потерь с учетом регуляризации (бинарная классификация)
$$ J_{reg}(W) = -\frac{1}{n} \sum y \cdot log(a^{(L)}) + (1-y) \cdot log(1-a^{(L)}) + $$
$$ + \frac{\alpha}{2n} \sum_l \sum_k \sum_j W^{(l)}_{k,j} $$
Уточним нотацию, мы находим уровень ошибки на основе значений выходного слоя $a^{(L)}$. Кроме того, мы добавляем значение регуляризации, которое рассчитывается как сумма $\sum_l$ сумм весов слоев $k$ и $j$ ($\sum_k$ и $\sum_j$). Приведем код.
|
1 2 3 4 5 6 7 8 9 10 |
def objective(y, y_pred, n, alpha): y_one_loss = y * np.log(y_pred + 1e-9) y_zero_loss = (1 - y) * np.log(1 - y_pred + 1e-9) log_loss = - np.sum(y_zero_loss + y_one_loss) / n # по умолчанию np.sum() складывает по всем измерениям reg_loss = (np.sum(W1**2) + np.sum(W2**2)) * alpha / (2 * n) return log_loss + reg_loss |
Реализуем модель с регуляризацией на Питоне на основе уже созданного алгоритма бинарной классификации со смещением с двумя признаками и одним скрытым слоем (три нейрона) и сравним результаты обучения.
Подготовка данных
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
from sklearn import datasets data = datasets.load_wine() df = pd.DataFrame(data.data, columns = data.feature_names) df['target'] = data.target df = df[df.target != 2] X = df[['alcohol', 'proline']] y = df['target'] X = (X - X.mean()) / X.std() X = X.to_numpy().T y = y.to_numpy().reshape(1, -1) |
Обучение модели
Обучим модель.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
def sigmoid(z): s = 1 / (1 + np.exp(-z)) return s np.random.seed(33) W1 = np.random.randn(3, 2) b1 = np.random.randn(3, 1) W2 = np.random.randn(1, 3) b2 = np.random.randn(1, 1) n = X.shape[1] epochs = 100000 learning_rate = 1 alpha = 0.1 A1 = X for i in range(epochs): # 3 х 2 на 2 х 130 Z1 = np.dot(W1, A1) + b1 A2 = sigmoid(Z1) # (3 x 130) # 1 х 3 на 3 х 130 Z2 = np.dot(W2, A2) + b2 A3 = sigmoid(Z2) # (1 x 130) loss = objective(A3, y, n, alpha) W2_delta = A3 - y # (1 x 130) W1_delta = np.dot(W2.T, W2_delta) * A2 * (1 - A2) # (3 x 130) # 1 х 130 на 130 х 3 W2_derivative = (np.dot(W2_delta, A2.T) + alpha * W2) / n # (1 x 3) b2_derivative = np.sum(W2_delta, keepdims = True) / n # (1 x 1) # 3 х 130 на 130 х 2 W1_derivative = (np.dot(W1_delta, A1.T) + alpha * W1) / n # (3 x 2) b1_derivative = np.sum(W1_delta, keepdims = True) / n # (1 x 1) W2 = W2 - learning_rate * W2_derivative b2 = b2 - learning_rate * b2_derivative W1 = W1 - learning_rate * W1_derivative b1 = b1 - learning_rate * b1_derivative if i % (epochs / 5) == 0: print('Эпоха:', i) print('Ошибка:', loss) print('-----------------------') time.sleep(0.5) print('Итоговая ошибка', loss) print('Нейросеть успешно обучена') |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
Эпоха: 0 Ошибка: 10.082518872092187 ----------------------- Эпоха: 20000 Ошибка: 1.1736216908788164 ----------------------- Эпоха: 40000 Ошибка: 1.1736172913272431 ----------------------- Эпоха: 60000 Ошибка: 1.173617288499269 ----------------------- Эпоха: 80000 Ошибка: 1.1736172884974607 ----------------------- Итоговая ошибка 1.1736172884974607 Нейросеть успешно обучена |
Сделаем прогноз.
|
1 2 3 4 5 6 7 8 9 10 |
from sklearn.metrics import accuracy_score Z1 = np.matmul(W1, A1) + b1 A2 = sigmoid(Z1) Z2 = np.matmul(W2, A2) + b2 A3 = sigmoid(Z2) y_pred, y_true = A3.flatten() > 0.5, y.flatten() accuracy_score(y_true, y_pred) |
|
1 |
0.9615384615384616 |
Выведем веса.
|
1 |
W1, W2 |
|
1 2 3 |
(array([[-1.757, -2.494], [-1.525, -1.663], [ 1.479, 1.653]]), array([[ 4.543, 3.227, -3.486]])) |
По сравнению с моделью без регуляризаци, точность на обучающей выборке, а также веса модели снизились.
Регуляризация в библиотеке Keras
Приведем регуляризацию модели в библиотеки Keras.
|
1 |
import tensorflow as tf |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
np.random.seed(42) tf.random.set_seed(42) model = tf.keras.models.Sequential([ tf.keras.layers.Dense(3, activation = 'sigmoid', use_bias = True, kernel_regularizer = tf.keras.regularizers.l2(0.01)), tf.keras.layers.Dense(1, activation = 'sigmoid', use_bias = True, kernel_regularizer = tf.keras.regularizers.l2(0.01)) ]) sgd = tf.keras.optimizers.SGD(learning_rate = 1, momentum = 0, nesterov = False) model.compile(optimizer = sgd, loss = 'binary_crossentropy', metrics = ['accuracy']) model.fit(X.T, y.T, epochs = 10000, batch_size = 130, verbose = 0) model.summary() |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
Model: "sequential_2" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_4 (Dense) (130, 3) 9 dense_5 (Dense) (130, 1) 4 ================================================================= Total params: 13 Trainable params: 13 Non-trainable params: 0 _________________________________________________________________ |
|
1 |
model.history.history['accuracy'][-1] |
|
1 |
0.9538461565971375 |
В целом регуляризаторы в Keras можно задавать следующим образом.
|
1 2 3 4 |
# l1, l2 и ElasticNet tf.keras.regularizers.l1(0.) tf.keras.regularizers.l2(0.) tf.keras.regularizers.l1_l2(l1 = 0.01, l2 = 0.01) |
Подведем итог
На сегодняшнем занятии мы изучили концепции смещения и разброса модели, рассмотрели принцип L1 и L2 регуляризации и протестировали регуляризацию на линейной регрессии и нейросети. Также мы познакомились с алгоритмами координатного и субградиентного спуска.
В заключение, приведем советы Эндрю Ына по тому, что делать, если модель не показывает нужные результаты (то есть имеет высокое смещение или разброс):
- увеличить обучающую выборку
- уменьшить количество признаков
- найти или создать новые признаки
- использовать полиномиальные признаки или увеличить количество слоев/нейронов в нейросети
- уменьшить или увеличить параметр регуляризации $ \alpha $
Дополнительные материалы
Бэггинг для снижения разброса
Нам не обязательно использовать прогноз только одной модели. Можно взять группу или ансамбль (от франц. ensemble — «вместе») моделей.
На курсе «ML для продолжающих» мы поговорим про техники ансамблирования (ensemble methods) или объединения алгоритмов.
Сейчас же давайте рассмотрим один из этих способов, а именно бэггинг (bagging) и постараемся с его помощью снизить разброс модели.
Про бэггинг
Бэггинг (bagging) или bootstrap aggregating предполагает три основных шага:
- Bootstrapping. За счет случайных выборок с возвращением (random samples with replacement) создается несколько датасетов на основе исходных данных (subsets). Это означает, что в каждом датасете могут быть как повторяющиеся объекты, так и объекты из других датасетов.
- Parallel training. Затем модели (их называют базовыми моделями, base estimators, или weak learners) обучаются параллельно и независимо друг от друга.
- Aggregation. Наконец, в зависимости от типа задачи, т.е. регрессии или классификации, рассчитывается, соответственно, среднее значение (soft voting) или класс, предсказанный большинством (hard/majority voting).
Алгоритм решающего дерева
Рассмотрение решающих деревьев (decision trees), алгоритма, который мы будем использовать внутри бэггинга, выходит за рамки сегодняшнего занятия. Мы начали знакомиться с этой темой на занятии работе с выбросами и более детально изучим на последующих курсах.
При этом будет важно сказать, что одним из недостатков этого алгоритма (когда используется только одно дерево) как раз является склонность к переобучению и высокий разброс модели. Посмотрим, сможет ли бэггинг исправить ситуацию.
Подготовка данных
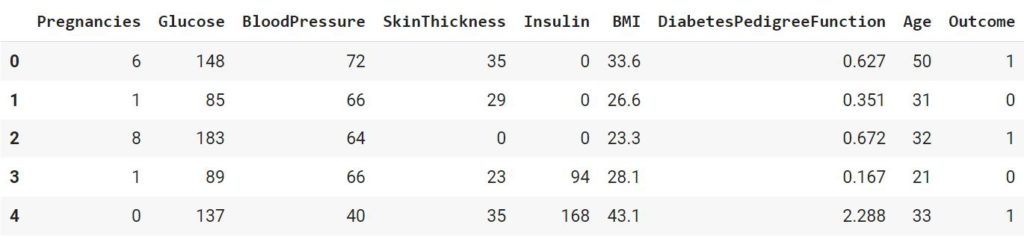
Используем данные о пациентах с диабетом.
|
1 2 |
diabetes = pd.read_csv('/content/diabetes.csv') diabetes.head() |
|
1 2 3 4 5 6 |
X = diabetes.drop(columns = 'Outcome') y = diabetes.Outcome X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 42) |
|
1 2 3 4 5 6 7 8 9 10 |
from sklearn.tree import DecisionTreeClassifier model = DecisionTreeClassifier(max_depth = 10, random_state = 42) model.fit(X_train, y_train) y_pred_train = model.predict(X_train) y_pred_test = model.predict(X_test) print('train: ' + str(accuracy_score(y_train, y_pred_train))) print('test: ' + str(accuracy_score(y_test, y_pred_test))) |
|
1 2 |
train: 0.9795158286778398 test: 0.696969696969697 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
from sklearn.ensemble import BaggingClassifier # в версии sklearn 1.2 параметр называет estimator bag_model = BaggingClassifier(base_estimator = model, n_estimators = 100, bootstrap = True, # выборка с возвращением random_state = 42) bag_model.fit(X_train, y_train) y_pred_train = bag_model.predict(X_train) y_pred_test = bag_model.predict(X_test) print('train: ' + str(accuracy_score(y_train, y_pred_train))) print('test: ' + str(accuracy_score(y_test, y_pred_test))) |
|
1 2 |
train: 1.0 test: 0.7532467532467533 |
Перейдем к теме градиентного спуска.