Все курсы > Анализ и обработка данных > Занятие 9
Отдельным вопросом работы с количественными данными являются выбросы (outliers), которые существенно влияют на многие статистические показатели, мешают масштабировать данные и ухудшают качество моделей машинного обучения.
Откроем ноутбук к этому занятию⧉
Для визуализации некоторых результатов потребуется обновить sklearn и перезапустить среду выполнения.
|
1 2 |
# на момент написания кода с 1.0.2 до 1.2.0 !pip install -U scikit-learn |
Про выбросы
Понятие и причины выбросов
Выбросы — это данные, которые сильно отличаются от общего распределения. При этом можно выделить:
- ошибочно возникающие выбросы
- человеческий фактор, ошибка ввода данных
- погрешности измерения
- ошибка эксперимента (например, шум при записи голоса)
- ошибка обработки
- ошибки получения выборки (sampling error)
- естественные выбросы
- высокий человек, разовая большая покупка
- аномально низкая цена на отдельный объект недвижимости
Примечание. В последнем случае, хотя с точки зрения модели такой выброс будет считаться нежелательным, имеет смысл проверить, с чем связана такая цена.
Влияние выбросов
Статистические показатели. На занятии по статистическому выводу мы провели тест Стьюдента, для того, чтобы определить на основе выборки вероятность того, что средний рост составляет 182 см.
|
1 2 3 |
np.random.seed(42) height = list(np.round(np.random.normal(180, 10, 1000))) print(height) |
|
1 |
[185.0, 179.0, 186.0, 195.0, 178.0, 178.0, 196.0, 188.0, 175.0, 185.0, 175.0, 175.0, 182.0, 161.0, 163.0, 174.0, 170.0, 183.0, 171.0, 166.0, 195.0, 178.0, 181.0, 166.0, 175.0, 181.0, 168.0, 184.0, 174.0, 177.0, 174.0, 199.0, 180.0, 169.0, 188.0, 168.0, 182.0, 160.0, 167.0, 182.0, 187.0, 182.0, 179.0, 177.0, 165.0, 173.0, 175.0, 191.0, 183.0, 162.0, 183.0, 176.0, 173.0, 186.0, 190.0, 189.0, 172.0, 177.0, 183.0, 190.0, 175.0, 178.0, 169.0, 168.0, 188.0, 194.0, 179.0, 190.0, 184.0, 174.0, 184.0, 195.0, 180.0, 196.0, 154.0, 188.0, 181.0, 177.0, 181.0, 160.0, 178.0, 184.0, 195.0, 175.0, 172.0, 175.0, 189.0, 183.0, 175.0, 185.0, 181.0, 190.0, 173.0, 177.0, 176.0, 165.0, 183.0, 183.0, 180.0, 178.0, 166.0, 176.0, 177.0, 172.0, 178.0, 184.0, 199.0, 182.0, 183.0, 179.0, 161.0, 180.0, 181.0, 205.0, 178.0, 183.0, 180.0, 168.0, 191.0, 188.0, 188.0, 171.0, 194.0, 166.0, 186.0, 202.0, 170.0, 174.0, 181.0, 175.0, 164.0, 181.0, 169.0, 185.0, 171.0, 195.0, 172.0, 177.0, 188.0, 168.0, 182.0, 193.0, 164.0, 182.0, 183.0, 188.0, 168.0, 167.0, 185.0, 183.0, 183.0, 183.0, 173.0, 182.0, 183.0, 173.0, 199.0, 185.0, 168.0, 187.0, 170.0, 188.0, 192.0, 172.0, 190.0, 184.0, 188.0, 199.0, 178.0, 172.0, 171.0, 172.0, 179.0, 183.0, 183.0, 188.0, 180.0, 195.0, 177.0, 207.0, 186.0, 171.0, 169.0, 185.0, 178.0, 187.0, 185.0, 179.0, 172.0, 165.0, 176.0, 189.0, 182.0, 168.0, 182.0, 184.0, 171.0, 182.0, 181.0, 169.0, 184.0, 186.0, 191.0, 191.0, 166.0, 171.0, 185.0, 185.0, 185.0, 219.0, 186.0, 191.0, 190.0, 187.0, 177.0, 188.0, 172.0, 178.0, 175.0, 181.0, 203.0, 161.0, 187.0, 164.0, 175.0, 191.0, 181.0, 169.0, 173.0, 187.0, 173.0, 182.0, 180.0, 173.0, 201.0, 186.0, 160.0, 182.0, 173.0, 189.0, 172.0, 179.0, 185.0, 189.0, 168.0, 177.0, 175.0, 173.0, 198.0, 184.0, 167.0, 189.0, 201.0, 190.0, 165.0, 175.0, 193.0, 173.0, 184.0, 188.0, 171.0, 179.0, 148.0, 170.0, 177.0, 168.0, 196.0, 166.0, 176.0, 181.0, 194.0, 166.0, 192.0, 180.0, 170.0, 185.0, 182.0, 174.0, 181.0, 176.0, 181.0, 187.0, 196.0, 168.0, 201.0, 160.0, 178.0, 186.0, 183.0, 174.0, 178.0, 175.0, 174.0, 188.0, 184.0, 173.0, 189.0, 183.0, 188.0, 186.0, 172.0, 174.0, 187.0, 186.0, 180.0, 181.0, 193.0, 174.0, 185.0, 178.0, 178.0, 191.0, 188.0, 188.0, 193.0, 180.0, 187.0, 177.0, 183.0, 179.0, 181.0, 186.0, 172.0, 201.0, 170.0, 168.0, 192.0, 188.0, 186.0, 186.0, 180.0, 171.0, 181.0, 173.0, 190.0, 179.0, 172.0, 177.0, 184.0, 174.0, 172.0, 182.0, 182.0, 175.0, 175.0, 182.0, 166.0, 166.0, 173.0, 178.0, 183.0, 195.0, 189.0, 178.0, 180.0, 170.0, 180.0, 177.0, 183.0, 172.0, 185.0, 195.0, 179.0, 184.0, 187.0, 176.0, 182.0, 180.0, 181.0, 172.0, 180.0, 185.0, 195.0, 190.0, 202.0, 172.0, 189.0, 182.0, 202.0, 172.0, 172.0, 174.0, 159.0, 175.0, 172.0, 182.0, 183.0, 199.0, 190.0, 174.0, 171.0, 185.0, 167.0, 198.0, 192.0, 175.0, 163.0, 194.0, 179.0, 192.0, 164.0, 174.0, 180.0, 180.0, 175.0, 186.0, 169.0, 179.0, 181.0, 185.0, 187.0, 169.0, 165.0, 193.0, 183.0, 173.0, 196.0, 181.0, 192.0, 181.0, 201.0, 198.0, 178.0, 190.0, 186.0, 194.0, 170.0, 187.0, 191.0, 162.0, 168.0, 160.0, 177.0, 187.0, 195.0, 181.0, 196.0, 166.0, 163.0, 179.0, 184.0, 180.0, 159.0, 179.0, 167.0, 187.0, 184.0, 171.0, 175.0, 169.0, 179.0, 190.0, 170.0, 185.0, 175.0, 172.0, 179.0, 170.0, 174.0, 168.0, 200.0, 180.0, 173.0, 182.0, 179.0, 178.0, 186.0, 188.0, 175.0, 174.0, 177.0, 157.0, 165.0, 194.0, 196.0, 178.0, 186.0, 183.0, 211.0, 191.0, 179.0, 170.0, 164.0, 182.0, 172.0, 166.0, 174.0, 169.0, 197.0, 189.0, 180.0, 195.0, 181.0, 171.0, 195.0, 185.0, 170.0, 178.0, 171.0, 166.0, 189.0, 199.0, 166.0, 186.0, 173.0, 175.0, 174.0, 171.0, 180.0, 172.0, 183.0, 179.0, 178.0, 171.0, 174.0, 188.0, 185.0, 170.0, 181.0, 188.0, 163.0, 185.0, 173.0, 186.0, 172.0, 162.0, 164.0, 180.0, 183.0, 171.0, 186.0, 163.0, 179.0, 168.0, 173.0, 180.0, 171.0, 176.0, 190.0, 174.0, 188.0, 169.0, 185.0, 194.0, 155.0, 172.0, 186.0, 178.0, 184.0, 174.0, 181.0, 178.0, 192.0, 183.0, 183.0, 176.0, 175.0, 176.0, 184.0, 176.0, 183.0, 201.0, 189.0, 177.0, 192.0, 176.0, 160.0, 170.0, 161.0, 176.0, 180.0, 197.0, 183.0, 178.0, 188.0, 158.0, 182.0, 188.0, 165.0, 191.0, 183.0, 176.0, 186.0, 203.0, 182.0, 182.0, 175.0, 172.0, 188.0, 171.0, 181.0, 175.0, 185.0, 183.0, 190.0, 175.0, 177.0, 170.0, 176.0, 184.0, 188.0, 171.0, 189.0, 194.0, 184.0, 199.0, 172.0, 168.0, 162.0, 195.0, 187.0, 179.0, 183.0, 169.0, 204.0, 181.0, 181.0, 187.0, 185.0, 182.0, 172.0, 185.0, 199.0, 193.0, 196.0, 175.0, 170.0, 179.0, 181.0, 191.0, 163.0, 195.0, 178.0, 176.0, 170.0, 163.0, 188.0, 181.0, 167.0, 167.0, 177.0, 197.0, 177.0, 165.0, 178.0, 177.0, 153.0, 179.0, 178.0, 187.0, 198.0, 191.0, 177.0, 169.0, 206.0, 181.0, 180.0, 180.0, 182.0, 179.0, 174.0, 175.0, 180.0, 175.0, 173.0, 181.0, 177.0, 195.0, 153.0, 191.0, 192.0, 159.0, 177.0, 176.0, 166.0, 172.0, 169.0, 198.0, 189.0, 193.0, 187.0, 169.0, 175.0, 185.0, 168.0, 187.0, 178.0, 176.0, 187.0, 184.0, 176.0, 192.0, 169.0, 186.0, 186.0, 177.0, 183.0, 167.0, 189.0, 178.0, 175.0, 190.0, 173.0, 166.0, 164.0, 186.0, 167.0, 198.0, 159.0, 197.0, 182.0, 179.0, 175.0, 184.0, 180.0, 191.0, 181.0, 182.0, 176.0, 179.0, 183.0, 163.0, 167.0, 187.0, 182.0, 178.0, 180.0, 183.0, 175.0, 172.0, 182.0, 170.0, 184.0, 163.0, 190.0, 185.0, 183.0, 190.0, 197.0, 190.0, 162.0, 167.0, 174.0, 180.0, 185.0, 173.0, 182.0, 172.0, 174.0, 166.0, 171.0, 166.0, 170.0, 191.0, 171.0, 206.0, 185.0, 182.0, 171.0, 187.0, 174.0, 181.0, 206.0, 179.0, 191.0, 173.0, 180.0, 198.0, 174.0, 198.0, 187.0, 174.0, 186.0, 190.0, 186.0, 164.0, 173.0, 178.0, 179.0, 186.0, 182.0, 167.0, 184.0, 186.0, 186.0, 191.0, 188.0, 185.0, 179.0, 163.0, 184.0, 182.0, 183.0, 167.0, 169.0, 191.0, 180.0, 187.0, 180.0, 180.0, 189.0, 175.0, 181.0, 175.0, 176.0, 177.0, 182.0, 175.0, 193.0, 171.0, 178.0, 176.0, 194.0, 182.0, 190.0, 165.0, 183.0, 189.0, 181.0, 191.0, 175.0, 194.0, 203.0, 176.0, 176.0, 195.0, 196.0, 175.0, 176.0, 177.0, 167.0, 171.0, 170.0, 172.0, 180.0, 182.0, 196.0, 170.0, 190.0, 178.0, 180.0, 187.0, 169.0, 184.0, 182.0, 185.0, 183.0, 205.0, 174.0, 175.0, 174.0, 174.0, 174.0, 192.0, 194.0, 174.0, 172.0, 185.0, 174.0, 186.0, 182.0, 165.0, 195.0, 198.0, 174.0, 176.0, 183.0, 183.0, 187.0, 200.0, 178.0, 172.0, 166.0, 173.0, 180.0, 198.0, 175.0, 182.0, 180.0, 192.0, 205.0, 175.0, 175.0, 190.0, 187.0, 198.0, 186.0, 176.0, 186.0, 191.0, 188.0, 185.0, 191.0, 192.0, 194.0, 186.0, 178.0, 181.0, 192.0, 172.0, 184.0, 176.0, 180.0, 193.0, 182.0, 180.0, 166.0, 187.0, 186.0, 202.0, 177.0, 182.0, 182.0, 196.0, 179.0, 183.0, 186.0, 182.0, 176.0, 182.0, 191.0, 170.0, 181.0, 173.0, 192.0, 165.0, 174.0, 184.0, 196.0, 179.0, 174.0, 199.0, 166.0, 158.0, 184.0, 175.0, 170.0, 187.0, 182.0, 174.0, 167.0, 189.0, 187.0, 179.0, 198.0, 169.0, 165.0, 173.0, 180.0, 182.0, 178.0, 184.0, 167.0, 194.0, 179.0, 191.0, 183.0, 185.0, 186.0, 184.0, 186.0, 193.0, 182.0, 187.0, 179.0, 194.0, 173.0, 198.0, 180.0, 166.0, 181.0, 173.0, 188.0, 173.0, 176.0, 161.0, 175.0, 156.0, 164.0, 188.0, 188.0, 184.0, 170.0, 180.0, 180.0, 168.0, 195.0, 189.0, 178.0, 180.0, 182.0, 160.0, 178.0, 173.0, 170.0, 177.0, 198.0, 186.0, 174.0, 186.0] |
Напомню, что исходя из данных мы смогли отвергнуть нулевую гипотезу, которая утверждала, что рост дейсвительно составляет 182 см.
|
1 2 3 |
import scipy.stats as st t_statistic, p_value = st.ttest_1samp(height, 182) p_value |
|
1 |
9.035492171563733e-09 |
Добавим выброс и повторно проверим гипотезу.
|
1 2 3 4 |
height.append(1000) t_statistic, p_value = st.ttest_1samp(height, 182) p_value |
|
1 |
0.26334958447468043 |
Как мы видим, одно сильно отличающееся наблюдение изменило результаты теста.
Масштабирование данных. Как мы только что видели, сильно отличающиеся от остальных значения мешают качественному масштабированию данных.
Модели ML. Выбросы влияют на качество модели линейной регрессии. Возьмем третий набор данных из квартета Энскомба (Anscombe’s quartet).
|
1 2 3 |
anscombe = pd.read_json('/content/sample_data/anscombe.json') anscombe = anscombe[anscombe.Series == 'III'] anscombe.head() |

|
1 2 |
x = anscombe.X y = anscombe.Y |
|
1 2 3 4 5 6 7 8 9 |
plt.scatter(x, y) slope, intercept = np.polyfit(x, y, deg = 1) x_vals = np.linspace(0, 20, num = 1000) y_vals = intercept + slope * x_vals plt.plot(x_vals, y_vals, 'r') plt.show() |

Посмотрим на коэффициент корреляции.
|
1 |
np.corrcoef(x, y)[0][1] |
|
1 |
0.8162867394895984 |
Удалим выброс.
|
1 2 3 |
# будем считать выбросом наблюдение с индексом 24 x.drop(index = 24, inplace = True) y.drop(index = 24, inplace = True) |
Вновь посмотрим на график и коэффициент корреляции.
|
1 2 3 4 5 6 7 8 9 |
plt.scatter(x, y) slope, intercept = np.polyfit(x, y, deg = 1) x_vals = np.linspace(0, 20, num = 1000) y_vals = intercept + slope * x_vals plt.plot(x_vals, y_vals, 'r') plt.show() |

|
1 |
np.corrcoef(x, y)[0][1] |
|
1 |
0.9999965537848283 |
Выбросы особенно сильны, когда мы располагаем небольшим количеством данных.
Outlier vs. Novelty
Отличающееся наблюдение можно разделить на выбросы (outlier) и новые отличающиеся наблюдения (novelty). Выброс уже присутствует в данных. То есть мы смотрим на данные и понимаем, что часть содержащихся в них наблюдений существенно отличаются от общей массы. Во втором случае, у нас уже есть набор данных, нас просят определить, является ли новое наблюдение выбросом или нет.
Так как для выявления уже присутствующих выбросов у нас нет никакой разметки, это обучение без учителя. Во втором случае, это частичное обучение с учителем (semi-supervised). На практике это означает, что при использовании продвинутых алгоритмов для выявления выбросов, если речь идет о новых отличающихся наблюдениях (novelty), мы должны использовать .fit() на обучающей выборке, а .predict(), .decision_function() и .score_samples() на тестовой (про алгоритмы и эти методы поговорим дальше). Подробнее здесь⧉.
Работа с выбросами
Начнем с более простых методов. Скачаем и подгрузим данные.
|
1 |
boston = pd.read_csv('/content/boston.csv') |
Статистические методы
boxplot
Выбросы можно увидеть на boxplot. По умолчанию, длина «усов» рассчитывается как $ 1,5 \times IQR $. Данные, которые выходят за их пределы — выбросы.
|
1 |
sns.boxplot(x = boston.RM); |

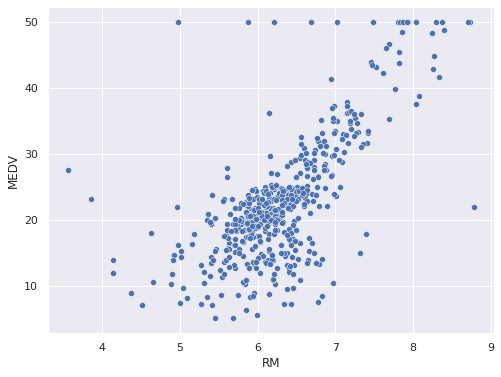
scatter plot
Кроме того, выбросы можно попытаться выявить на точечной диаграмме.
|
1 |
sns.scatterplot(x = boston.RM, y = boston.MEDV); |
z-score
Количественно выбросы можно найти через стандартизированную оценку (z-оценку, z-score). Эта оценка показывает на сколько средних квадратических отклонений значение отличается от среднего.
|
1 2 3 4 |
from scipy import stats z = stats.zscore(boston) z.head() |

Так как мы знаем, что 99,7 процентов наблюдений лежат в пределах трех СКО от среднего, то можем предположить, что выбросами будут оставшиеся 0,3 процента.

Выведем эти значения.
|
1 2 3 4 |
# найдем те значения, которые отклоняются больше чем на три СКО # технически, метод .any() выводит True для тех строк (axis = 1), # где хотя бы одно значение True (т.е. > 3) boston[(np.abs(z) > 3).any(axis = 1)].head() |

Посмотрим, как удалить выбросы в отдельном столбце.
|
1 2 3 4 5 |
# выведем True там, где в столбце RM значение меньше трех СКО col_mask = np.where(np.abs(z.RM) < 3, True, False) # применим маску к столбцу boston.RM[col_mask].head() |
|
1 2 3 4 5 6 |
0 6.575 1 6.421 2 7.185 3 6.998 4 7.147 Name: RM, dtype: float64 |
Теперь удалим выбросы во всем датафрейме.
|
1 2 3 4 5 6 |
# если в строке (axis = 1) есть хотя бы один False как следствие условия np.abs(z) < 3 # метод .all() вернет логический массив, который можно использовать как фильтр z_mask = (np.abs(z) < 3).all(axis = 1) boston_z = boston[z_mask] boston_z.shape |
|
1 |
(415, 14) |
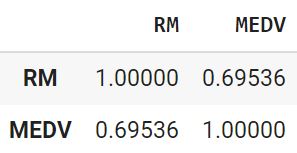
Выведем корреляцию до и после удаления выбросов.
|
1 |
boston[['RM', 'MEDV']].corr() |
|
1 |
boston_z[['RM', 'MEDV']].corr() |

В данном случае корреляция увеличилась.
Измененный z-score
Важно понимать, что z-score, который мы используем для идентификации выбросов сам по себе зависит от сильно отличающихся значений, поскольку для расчета используется среднее арифметическое и СКО.
$$ z = \frac {x-\mu}{\sigma} $$
Вместо z-оценки можно использовать изменнную z-оценку (modified z-score), которая использует метрики робастной статистики.
$$ z_{mod} = \frac{x-Q2}{MAD} $$
где MAD представляет собой среднее абсолютное отклонение (median absolute deviation) и рассчитывается по формуле $MAD = median(|x-Q2|). Заметим⧉, что $MAD=0,6745\sigma$.
Iglewicz и Hoaglin рекомендуют считать выбросами те значения, для которых $|z_{mod} > 3,5|$. Применим этот метод.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# рассчитаем MAD median = boston.median() dev_median = boston - (boston.median()) abs_dev_median = np.abs(dev_median) MAD = abs_dev_median.median() # рассчитаем измененный z-score # добавим константу, чтобы избежать деления на ноль zmod = (0.6745 * (boston - boston.median())) / (MAD + 1e-5) # создадим фильтр zmod_mask = (np.abs(zmod) < 3.5).all(axis = 1) # выведем результат boston_zmod = boston[zmod_mask] boston_zmod.shape |
|
1 |
(168, 14) |
Обратите внимание, что в данном случае мы очень агрессивно удаляли значения. Посмотрим на корреляцию.
|
1 |
boston_zmod[['RM', 'MEDV']].corr().iloc[0, 1].round(3) |
|
1 |
0.719 |
1.5 IQR
Еще одним распространенным способом выявления и удаления выбросов является правило $ 1,5 \times IQR $. Рассмотрим, почему именно 1,5? В стандартном нормальном распределении Q1 и Q3 соответствуют $-0.6745\sigma$ и $0.6745\sigma$.

Зная эти показатели, мы можем рассчитать верхнюю и нижнюю границу.
|
1 2 3 4 5 6 7 8 9 10 11 |
q1 = -0.6745 q3 = 0.6745 iqr = q3 - q1 lower_bound = q1 - (1.5 * iqr) upper_bound = q3 + (1.5 * iqr) # тогда lower_bound и upper_bound почти равны трем СКО от среднего # (было бы точнее, если использовать 1.75) print(lower_bound, upper_bound) |
|
1 |
-2.698 2.698 |
Замечу, что для того, чтобы этот метод нахождения выбросов был аналогичен z-score, было бы точнее использовать показатель $ 1,75 \times IQR $. При таком решении выбросами будет считаться большее количество наблюдений.
Найдем и удалим выбросы в столбце.
|
1 2 3 4 5 6 7 8 9 10 |
# найдем границы 1.5 * IQR q1 = boston.RM.quantile(0.25) q3 = boston.RM.quantile(0.75) iqr = q3 - q1 lower_bound = q1 - (1.5 * iqr) upper_bound = q3 + (1.5 * iqr) print(lower_bound, upper_bound) |
|
1 |
4.778499999999999 7.730500000000001 |
|
1 2 |
# применим эти границы, чтобы найти выбросы в столбце RM boston[(boston.RM < lower_bound) | (boston.RM > upper_bound)].head() |

|
1 2 |
# найдем значения без выбросов (переворачиваем маску) boston[~(boston.RM < lower_bound) | (boston.RM > upper_bound)].head() |

Найдем и удалим выбросы во всем датафрейме.
|
1 2 3 4 5 6 7 8 9 |
# найдем границы 1.5 * IQR по каждому столбцу Q1 = boston.quantile(0.25) Q3 = boston.quantile(0.75) IQR = Q3 - Q1 lower, upper = Q1 - 1.5 * IQR, Q3 + 1.5 * IQR # создадим маску для выбросов # (если хотя бы один выброс в строке (True), метод .any() сделает всю строку True mask_out = ((boston < lower) | (boston > upper)).any(axis = 1) |
|
1 2 |
# найдем выбросы во всем датафрейме boston[mask_out].shape |
|
1 |
(238, 14) |
|
1 2 |
# возьмем датафрейм без выбросов boston[~mask_out].shape |
|
1 |
(268, 14) |
|
1 2 3 |
# обратное условие, если все значения по всем строкам внутри границ # метод .all() выдаст True mask_no_out = ((boston >= lower) & (boston <= upper)).all(axis = 1) |
|
1 2 |
# выведем датафрейм без выбросов boston[mask_no_out].shape |
|
1 |
(268, 14) |
|
1 2 |
# выведем выбросы boston[~mask_no_out].shape |
|
1 |
(238, 14) |
|
1 2 |
# сохраним результат boston_iqr = boston[mask_no_out] |
|
1 |
boston_iqr[['RM', 'MEDV']].corr() |

Как мы видим, несмотря на более активное удаление значений, коэффициент корреляции стал даже меньше, чем в изначальных данных.
Методы, основанные на модели
Теперь посмотрим на методы выявления выбросов, основанные на модели (model-based approaches)
Isolation Forest
Изолирующий лес (Isolation Forest или iForest) использует принципы решающего дерева (Decision Tree) и построенного на его основе ансамблевого метода случайного леса (Random Forest).
Принцип изолирующего леса
Принцип построения изолирующиего дерева (Isolation Tree или iTree) довольно прост. Алгоритм случайным образом выбирает признак, затем в пределах диапазона этого признака случайно выбирает разделяющую границу (split). Та часть наблюдений, которая меньше либо равна этой границые. оказывается в левом потомке (left child node), та которая больше — в правом (right child node). Затем процесс рекурсивно повторяется.
Что интересно, в получившейся древовидной структуре путь (то есть количество сплитов) от корневого узла (root node) до выброса будет существенно короче, чем до обычного наблюдения. Это логично, например, в задаче классификации с помощью решающего дерева в первую очередь удается отделить тот класс, который наиболее удален от остальных.
Приведем классификацию с помощью решающего дерева на примере датасета цветов ириса.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
from sklearn.tree import DecisionTreeClassifier from sklearn import tree from sklearn.datasets import load_iris iris = load_iris() df = pd.DataFrame(iris.data[:,[2,3]], columns = ['petal_l', 'petal_w']) df['target'] = iris.target X = df[['petal_l', 'petal_w']] y = df.target from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 1/3, random_state = 42) clf = DecisionTreeClassifier(criterion = 'entropy', max_leaf_nodes = 4, random_state = 42) clf.fit(X_train, y_train) plt.figure(figsize = (6,6)) tree.plot_tree(clf) plt.show() |

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
plt.figure(figsize = (9,9)) ax = plt.axes() sns.scatterplot(x = X_train.petal_l, y = X_train.petal_w, hue = df.target, palette = 'bright', s = 60) ax.vlines(x = 2.45, ymin = 0, ymax = 2.5, linewidth = 1, color = 'k', linestyles = '--') ax.text(1, 1.5, 'X[0] <= 2.45', fontsize = 12, bbox = dict(facecolor = 'none', edgecolor = 'k')) ax.hlines(y = 1.75, xmin = 2.45, xmax = 7, linewidth = 1, color = 'b', linestyles = '--') ax.text(3, 2.3, 'X[0] > 2.45 \nX[1] > 1.75', fontsize = 12, bbox = dict(facecolor = 'none', edgecolor = 'k')) ax.vlines(x = 5.35, ymin = 0, ymax = 1.75, linewidth = 1, color = 'r', linestyles = '--') ax.text(3, 0.5, 'X[0] > 2.45 \nX[1] <= 1.75 \nX[0] <= 5.35', fontsize = 12, bbox = dict(facecolor = 'none', edgecolor = 'k')) ax.text(5.5, 0.5, 'X[0] > 2.45 \nX[1] <= 1.75 \nX[0] > 5.35', fontsize = 12, bbox = dict(facecolor = 'none', edgecolor = 'k')) plt.xlabel('X[0]') plt.ylabel('X[1]') plt.show() |

Как вы видите, нулевой, наиболее удаленный класс (синие точки) удалось отделить уже на первом шаге. По этому же принципу отделяются выбросы.
Лес изолирующих деревьев соответственно дает усредненное расстояние до каждой из точек.
Показатель аномальности
Рассмотрим как количественно выразить среднее расстояние до каждой из точек или показатель аномальности (anomaly score). Приведем формулу.
$$ s(x, n) = 2^{-\frac{E(h(x))}{c(n)}} $$
где x — это конкретное наблюдение из общего числа n наблюдений. При этом c(n) — это средний путь до листа в аналогичном по структуре двоичном дереве поиска (binary search tree, BST) с n наблюдений, а $ E(h(x)) $ — усредненное по всем деревьям расстояние до конкретного наблюдения x. Нормализуя показатель $ E(h(x)) $ по c(n) мы получаем, что:
- когда $ E(h(x)) \rightarrow c(n), s \rightarrow 0,5 $
- когда $ E(h(x)) \rightarrow 0, s \rightarrow 1 $
- когда $ E(h(x)) \rightarrow n-1, s \rightarrow 0 $
При этом расстояние $h(x)$ находится в диапазоне $(0, n-1]$, а s в диапазоне $(0, 1]$. Таким образом,
- если наблюдение имеет s, близкое к 1, это выброс
- если наблюдение имеет s, близкое к 0, это не выброс
- если s всех наблюдений близко к 0,5, тогда вся выборка не имеет выбросов
Более подробно про этот алгоритм можно прочитать в публикации его создателей Liu, Fei Tony, Ting, Kai Ming and Zhou, Zhi-Hua. “Isolation forest.” Data Mining, 2008. ICDM’08. Eighth IEEE International Conference⧉.
IsolationForest в sklearn
Пример из sklearn
Разберем пример⧉, приведенный на сайте sklearn. Вначале создадим синтетические данные с выбросами.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
from sklearn.model_selection import train_test_split # зададим количество обычных наблюдений и выбросов n_samples, n_outliers = 120, 40 rng = np.random.RandomState(0) # создадим вытянутое (за счет умножения на covariance) covariance = np.array([[0.5, -0.1], [0.7, 0.4]]) # и сдвинутое вверх вправо shift = np.array([2, 2]) # облако объектов cluster_1 = 0.4 * rng.randn(n_samples, 2) @ covariance + shift # создадим сферическое и сдвинутое вниз влево облако объектов cluster_2 = 0.3 * rng.randn(n_samples, 2) + np.array([-2, -2]) # создадим выбросы outliers = rng.uniform(low = -4, high = 4, size = (n_outliers, 2)) # создадим пространство из двух признаков X = np.concatenate([cluster_1, cluster_2, outliers]) # а также целевую переменную (1 для обычных наблюдений, -1 для выбросов) y = np.concatenate( [np.ones((2 * n_samples), dtype = int), -np.ones((n_outliers), dtype=int)] ) scatter = plt.scatter(X[:, 0], X[:, 1], c = y, cmap = 'Paired', s = 20, edgecolor = 'k') plt.title('Обычные наблюдения распределены нормально, \nвыбросы - равномерно') plt.show() |

Разделим выборку.
|
1 2 3 4 5 6 7 8 9 10 |
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify = y, random_state = 42) # параметр stratify сделает так, что и в тестовой, и в обучающей выборке # будет одинаковая доля выбросов _, y_train_counts = np.unique(y_train, return_counts = True) _, y_test_counts = np.unique(y_test, return_counts = True) np.round(y_train_counts/len(y_train), 2), np.round(y_test_counts/len(y_test), 2) |
Обучим класс изолирующего леса. Так как наблюдений мало, для каждого дерева будем брать все объекты обучающей выборки.
|
1 2 3 4 5 |
from sklearn.ensemble import IsolationForest # обучим алгоритм isof = IsolationForest(max_samples = len(X_train), random_state = 0) isof.fit(X_train) |

Сделаем прогноз на тесте и посмотрим на результат.
|
1 2 3 4 |
y_pred = isof.predict(X_test) from sklearn.metrics import accuracy_score accuracy_score(y_test, y_pred) |
|
1 |
0.9428571428571428 |
Выведем решающую границу.
|
1 2 3 4 5 6 7 8 9 10 11 |
from sklearn.inspection import DecisionBoundaryDisplay disp = DecisionBoundaryDisplay.from_estimator( isof, X, response_method = 'predict', alpha = 0.5, ) disp.ax_.scatter(X[:, 0], X[:, 1], c=y, s=20, edgecolor="k") disp.ax_.set_title('Решающая граница изолирующего дерева') plt.show() |

Настройка гиперпараметров
Разберем гиперпараметры модели:
- n_estimators — количество деревьев в изолирующем лесу
- max_samples — количество наблюдений для обучения каждого изолирующего дерева
- max_features — количество признаков для обучения каждого дерева
- bootstrap — получение выборки (sampling) с возвращением (True) или без (False).
- contamination — доля выбросов в датасете
- значение auto определяет выбросы так, как это было описано в публикации авторов, но с измененным порогом: anomaly score выброса отрицателен и близок к $-1$, anomaly_score обычного наблюдения положителен и близок к 0
- кроме того, можно задать конкретную ожидаемую долю выбросов, например, 0,1 сделает выбросами 10 процентов наблюдений с самым высоким anomaly score
Продемонстрируем особенности параметра contamination на простом примере. Возьмем небольшой набор данных и поочередно применим параметры contamination = ‘auto’, 0.1, 0.2. Несколько пояснений:
- метод .predict() помечает обычные наблюдения значением 1, выбросы значением $-1$
- метод .decision_function() выдает anomaly_score
|
1 |
X_ = [[-1], [2], [3], [5], [7], [10], [12], [20], [30], [100]] |
|
1 2 3 |
clf = IsolationForest(contamination = 'auto', random_state = 42).fit(X_) print(clf.predict(X_)) print(clf.decision_function(X_)) |
|
1 2 3 |
[-1 1 1 1 1 1 1 1 -1 -1] [-0.00403873 0.10617494 0.11864618 0.11188085 0.11479849 0.09281731 0.0780247 0.00948311 -0.08497048 -0.27336568] |
|
1 2 3 |
clf = IsolationForest(contamination = 0.1, random_state = 42).fit(X_) print(clf.predict(X_)) print(clf.decision_function(X_)) |
|
1 2 3 |
[ 1 1 1 1 1 1 1 1 1 -1] [ 0.09977127 0.20998494 0.22245618 0.21569085 0.21860849 0.19662731 0.1818347 0.11329311 0.01883952 -0.16955568] |
|
1 2 3 |
clf = IsolationForest(contamination = 0.2, random_state = 42).fit(X_) print(clf.predict(X_)) print(clf.decision_function(X_)) |
|
1 2 3 |
[ 1 1 1 1 1 1 1 1 -1 -1] [ 0.01618635 0.12640002 0.13887126 0.13210593 0.13502358 0.11304239 0.09824979 0.02970819 -0.0647454 -0.25314059] |
Датасет boston
Применим алгоритм изолирующего леса к датасету boston.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
X_boston = boston.drop(columns = 'MEDV') y_boston = boston.MEDV clf = IsolationForest(max_samples = 100, random_state = 0) clf.fit(X_boston) # создадим столбец с anomaly_score boston['scores'] = clf.decision_function(X_boston) # и результатом (выброс (-1) или нет (1)) boston['anomaly'] = clf.predict(X_boston) # посмотрим на количество выбросов boston[boston.anomaly == -1].shape[0] |
|
1 |
106 |
Посмотрим на взаимосвязь признака RM с целевой переменной после удаления выбросов.
|
1 2 |
boston_ifor = boston[boston.anomaly == 1] sns.scatterplot(x = boston_ifor.RM, y = boston_ifor.MEDV); |

Недостаток алгоритма
Для того чтобы увидеть недостаток алгоритма, рассмотрим тепловую карту, на которой цветом будут выводиться области с одинаковым anomaly score.
|
1 2 3 4 5 6 7 8 9 |
disp = DecisionBoundaryDisplay.from_estimator( isof, X, response_method = 'decision_function', alpha = 0.5, ) disp.ax_.scatter(X[:, 0], X[:, 1], c=y, s=20, edgecolor="k") disp.ax_.set_title('Anomaly score') plt.show() |
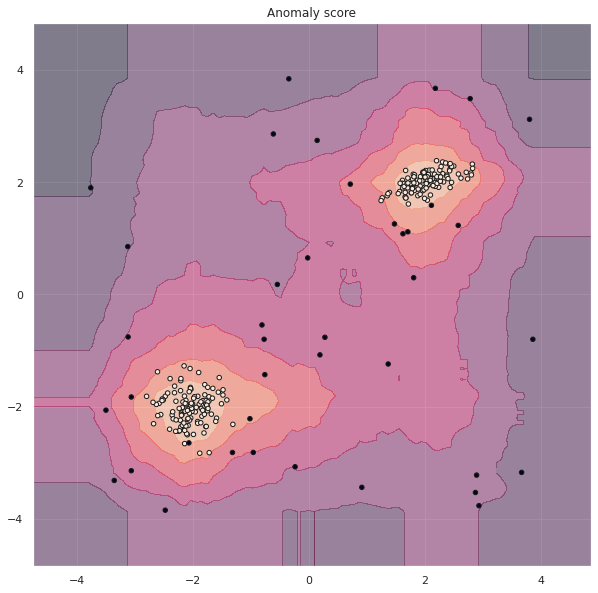
Как вы видите, в верхнем левом и нижнем правом углу также находятся области (их называют ghost areas), в которых объекты могли бы быть классифицированы как обычные наблюдения, хотя это неправильно (ложноположительный результат). Это связано с тем, что границы, проводимые алгоритмом параллельны осям координат.
Приведем иллюстрацию из статьи⧉ исследователей, усовершенствовавших этот алгоритм.

Для решения этой проблемы был предложен расширенный алгоритм изолирующего леса.
Extended Isolation Forest
Расширенный алгоритм изолирующего леса (Extended Isolation Forest) делит пространство с помощью случайных, не обязательно параллельных осям координат, гиперплоскостей. Авторами этого алгоритма являются Sahand Hariri, Matias Carrasco Kind и Rober J. Brunner⧉. Для данных на предыдущей иллюстрации разделение с помощью расширенного алгоритма могло бы выглядеть вот так.

Рассмотрим работу этого алгоритма на практике. Приведу две библиотеки, в которых реализован Extended Isolation Forest.
- Библиотека eif⧉, созданная авторами алгоритма; и
- Extended Isolation Forest на платфоме h2o⧉.
Используем второй вариант.
Платформа h2o
Установим h2o в Google Colab.
|
1 |
!pip install h2o |
Запустим сервер h2o.
|
1 2 3 |
import h2o h2o.init() |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
Checking whether there is an H2O instance running at http://localhost:54321 ..... not found. Attempting to start a local H2O server... Java Version: openjdk version "11.0.17" 2022-10-18; OpenJDK Runtime Environment (build 11.0.17+8-post-Ubuntu-1ubuntu218.04); OpenJDK 64-Bit Server VM (build 11.0.17+8-post-Ubuntu-1ubuntu218.04, mixed mode, sharing) Starting server from /usr/local/lib/python3.8/dist-packages/h2o/backend/bin/h2o.jar Ice root: /tmp/tmpztb87_pq JVM stdout: /tmp/tmpztb87_pq/h2o_unknownUser_started_from_python.out JVM stderr: /tmp/tmpztb87_pq/h2o_unknownUser_started_from_python.err Server is running at http://127.0.0.1:54321 Connecting to H2O server at http://127.0.0.1:54321 ... successful. H2O_cluster_uptime: 03 secs H2O_cluster_timezone: Etc/UTC H2O_data_parsing_timezone: UTC H2O_cluster_version: 3.38.0.3 H2O_cluster_version_age: 1 month and 1 day H2O_cluster_name: H2O_from_python_unknownUser_tcusbr H2O_cluster_total_nodes: 1 H2O_cluster_free_memory: 3.172 Gb H2O_cluster_total_cores: 2 H2O_cluster_allowed_cores: 2 H2O_cluster_status: locked, healthy H2O_connection_url: http://127.0.0.1:54321 H2O_connection_proxy: {"http": null, "https": null} H2O_internal_security: False Python_version: 3.8.16 final |
Обучение алгоритмов
Импортируем класс алгоритма⧉, создадим объекты этого класса для модели обычного изолирующего леса (без наклона гиперплоскостей) и для модели с максимальным наклоном гиперплоскостей.
Максимальный наклон задается параметром extension_level и находится в диапазоне $[0, P-1]$, где P — это количество признаков. В нашем случае признаков два, поэтому для расширенного алгоритма используем extension_level = 1.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
# импортируем класс Extended Isolation Forest from h2o.estimators import H2OExtendedIsolationForestEstimator # зададим основные параметры алгоритмов ntrees = 400 sample_size = len(X) seed = 42 # создадим специальный h2o датафрейм training_frame = h2o.H2OFrame(X) # создадим класс обычного изолирующего леса IF_h2o = H2OExtendedIsolationForestEstimator( model_id = "isolation_forest", ntrees = ntrees, sample_size = sample_size, extension_level = 0, seed = seed ) # обучим модель IF_h2o.train(training_frame = training_frame) # создадим класс расширенного изолирующего леса EIF_h2o = H2OExtendedIsolationForestEstimator( model_id = "extended_isolation_forest", ntrees = ntrees, sample_size = sample_size, extension_level = 1, seed = seed ) # обучим модель EIF_h2o.train(training_frame = training_frame) # выведем статистику по каждой из моделей print(IF_h2o) print(EIF_h2o) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
Parse progress: |████████████████████████████████████████████████████████████████| (done) 100% extendedisolationforest Model Build progress: |██████████████████████████████████| (done) 100% extendedisolationforest Model Build progress: |██████████████████████████████████| (done) 100% Model Details ============= H2OExtendedIsolationForestEstimator : Extended Isolation Forest Model Key: isolation_forest Model Summary: number_of_trees size_of_subsample extension_level seed number_of_trained_trees min_depth max_depth mean_depth min_leaves max_leaves mean_leaves min_isolated_point max_isolated_point mean_isolated_point min_not_isolated_point max_not_isolated_point mean_not_isolated_point min_zero_splits max_zero_splits mean_zero_splits -- ----------------- ------------------- ----------------- ------ ------------------------- ----------- ----------- ------------ ------------ ------------ ------------- -------------------- -------------------- --------------------- ------------------------ ------------------------ ------------------------- ----------------- ----------------- ------------------ 400 280 0 42 400 8 8 8 28 96 54.795 8 57 26.3275 223 272 253.673 1 32 12.875 Model Details ============= H2OExtendedIsolationForestEstimator : Extended Isolation Forest Model Key: extended_isolation_forest Model Summary: number_of_trees size_of_subsample extension_level seed number_of_trained_trees min_depth max_depth mean_depth min_leaves max_leaves mean_leaves min_isolated_point max_isolated_point mean_isolated_point min_not_isolated_point max_not_isolated_point mean_not_isolated_point min_zero_splits max_zero_splits mean_zero_splits -- ----------------- ------------------- ----------------- ------ ------------------------- ----------- ----------- ------------ ------------ ------------ ------------- -------------------- -------------------- --------------------- ------------------------ ------------------------ ------------------------- ----------------- ----------------- ------------------ 400 280 1 42 400 8 8 8 18 71 40.89 4 34 15.3075 246 276 264.692 2 33 14.6625 |
Сравнение алгоритмов
Так как Extended Isolation Forest — это алгоритм без учителя (метод .predict() выдает anomaly_score), мы не можем напрямую посчитать точность прогноза. С другой стороны, так как в созданных нами данных есть разметка, мы можем провести косвенное сравнение.
Например, мы можем отсортировать данные по anomaly_score в убывающем порядке (то есть в начале будут наблюдения, которые наиболее вероятно являются выбросами) и посмотреть, какое количество единиц (то есть не выбросов), оказалось в результатах сортировки каждого из алгоритмов.
Начнем с алгоритма обычного изолирующего леса. Сделаем прогноз.
|
1 2 3 4 5 6 |
# рассчитаем anomaly_score для обычного алгоритма h2o_anomaly_score_if = IF_h2o.predict(training_frame) # преобразуем результат в датафрейм h2o_anomaly_score_if_df = h2o_anomaly_score_if.as_data_frame(use_pandas = True, header = True) |
|
1 |
extendedisolationforest prediction progress: |███████████████████████████████████| (done) 100% |
|
1 2 |
# посмотрим на результат h2o_anomaly_score_if_df.head() |

Создадим датафрейм из исходных признаков и целевой переменной.
|
1 2 |
data = pd.DataFrame(X, columns = ['x1', 'x2']) data['target'] = y |
Определимся с долей наблюдений, в которых будем считать количество выбросов и не выбросов.
|
1 2 3 4 5 |
# выберем количество наблюдений sample = 60 # для наглядности рассчитаем долю от общего числа наблюдений sample / len(X) |
|
1 |
0.21428571428571427 |
Соединим датафрейм с признаками и целевой переменной с показателями аномальности. Затем отсортируем по этой метрике в убывающем порядке и рассчитаем количество выбросов и не выбросов в имеющихся данных.
|
1 2 3 |
if_df = pd.concat([data, h2o_anomaly_score_if_df], axis = 1) if_df.sort_values(by = 'anomaly_score', ascending = False, inplace = True) np.unique(if_df.iloc[:sample, 2], return_counts = True) |
|
1 |
(array([-1, 1]), array([39, 21])) |
Итак, в 60-ти наблюдениях с наибольшим anomaly score обычный алгоритм поместил 39 выбросов и 21 не выброс.
Сделаем то же самое с расширенным алгоритмом.
|
1 2 3 4 5 6 7 |
h2o_anomaly_score_eif = EIF_h2o.predict(training_frame) h2o_anomaly_score_eif_df = h2o_anomaly_score_eif.as_data_frame(use_pandas = True, header = True) eif_df = pd.concat([data, h2o_anomaly_score_eif_df], axis = 1) eif_df.sort_values(by = 'anomaly_score', ascending = False, inplace = True) np.unique(eif_df.iloc[:sample, 2], return_counts = True) |
|
1 2 |
extendedisolationforest prediction progress: |███████████████████████████████████| (done) 100% (array([-1, 1]), array([38, 22])) |
Расширенный алгоритм сделал чуть менее качественный прогноз.
Визуализация
Сравним тепловые карты обоих алгоритмов.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
granularity = 50 # сформируем данные для прогноза xx, yy = np.meshgrid(np.linspace(-5, 5, granularity), np.linspace(-5, 5, granularity)) hf_heatmap = h2o.H2OFrame(np.c_[xx.ravel(), yy.ravel()]) # сделаем прогноз с помощью двух алгоритмов h2o_anomaly_score_if = IF_h2o.predict(hf_heatmap) h2o_anomaly_score_df_if = h2o_anomaly_score_if.as_data_frame(use_pandas = True, header = True) heatmap_h2o_if = np.array(h2o_anomaly_score_df_if["anomaly_score"]).reshape(xx.shape) h2o_anomaly_score_eif = EIF_h2o.predict(hf_heatmap) h2o_anomaly_score_df_eif = h2o_anomaly_score_eif.as_data_frame(use_pandas = True, header = True) heatmap_h2o_eif = np.array(h2o_anomaly_score_df_eif["anomaly_score"]).reshape(xx.shape) |
|
1 2 3 |
Parse progress: |████████████████████████████████████████████████████████████████| (done) 100% extendedisolationforest prediction progress: |███████████████████████████████████| (done) 100% extendedisolationforest prediction progress: |███████████████████████████████████| (done) 100% |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
f = plt.figure(figsize=(24, 9)) # объявим функцию для вывода подграфиков def plot_heatmap(heatmap_data, subplot, title): ax1 = f.add_subplot(subplot) levels = np.linspace(0,1,10, endpoint = True) v = np.linspace(0, 1, 12, endpoint = True) v = np.around(v, decimals = 1) CS = ax1.contourf(xx, yy, heatmap_data, levels, cmap = plt.cm.YlOrRd) cbar = plt.colorbar(CS, ticks = v) cbar.ax.set_ylabel('Anomaly score', fontsize = 25) cbar.ax.tick_params(labelsize = 15) ax1.set_xlabel("x1", fontsize = 25) ax1.set_ylabel("x2", fontsize = 25) plt.tick_params(labelsize=30) plt.scatter(X[:,0],X[:,1],s=15,c='None',edgecolor='k') plt.axis("equal") plt.title(title, fontsize=32) # выведем тепловые карты plot_heatmap(heatmap_h2o_if, 121, "Isolation Forest") plot_heatmap(heatmap_h2o_eif, 122, "Extended Isolation Forest") plt.show() |

В данном случае, как мы видим, расширенному алгоритму не удалось сформировать два обособленных кластера.
Подведем итог
На сегодняшнем занятии мы разобрали статистические методы выявления выбросов (boxplot, scatter plot, z-score и 1,5 IQR), а также два метода, основанные на модели (алгоритмы обычного и расширенного изолирующего леса).
Перейдем к теме кодирования категориальных переменных.