Все курсы > Анализ и обработка данных > Занятие 5
На прошлом занятии, посвященном практике EDA, мы работали с «чистыми данными», то есть такими данными, в которых нет ни ошибок, ни пропущенных значений. К сожалению, так бывает далеко не всегда.
Сегодня мы научимся очищать данные от дубликатов, неверных и плохо отформатированных значений, а также исправлять ошибки в дате и времени. На следующем занятии мы поговорим про работу с пропусками.
Откроем ноутбук к этому занятию⧉
Ошибки в данных могут встречаться по многим причинам. Они могут быть связаны с человеческим фактором, например, простой невнимательностью, или вызваны сбоями в работе записывающего какие-либо показатели оборудования.
В качестве примера мы будем использовать несложный датасет, в котором содержатся данные за 2019 год об отдельных финансовых показателях сети магазинов одежды, представленной в нескольких городах мира. В частности, нам доступна следующая информация:
- month — за какой месяц сделана запись
- profit — прибыль (profit) по сети
- MoM — изменение выручки (revenue) сети по отношению к предыдущему месяцу
- high — магазин с наибольшей маржинальностью (margin) продаж
Создадим датафрейм из словаря.
|
1 2 3 4 5 6 7 |
financials = pd.DataFrame({'month' : ['01/01/2019', '01/02/2019', '01/03/2019', '01/03/2019', '01/04/2019', '01/05/2019', '01/06/2019', '01/07/2019', '01/08/2019', '01/09/2019', '01/10/2019', '01/11/2019', '01/12/2019', '01/12/2019'], 'profit' : ['1.20$', '1.30$', '1.25$', '1.25$', '1.27$', '1.11$', '1.23$', '1.20$', '1.31$', '1.24$', '1.18$', '1.17$', '1.23$', '1.23$'], 'MoM' : [0.03, -0.02, 0.01, 0.02, -0.01, -0.015, 0.017, 0.04, 0.02, 0.01, 0.00, -0.01, 2.00, 2.00], 'high' : ['Dubai', 'Paris', 'singapour', 'singapour', 'moscow', 'Paris', 'Madrid', 'moscow', 'london', 'london', 'Moscow', 'Rome', 'madrid', 'madrid'] }) financials |
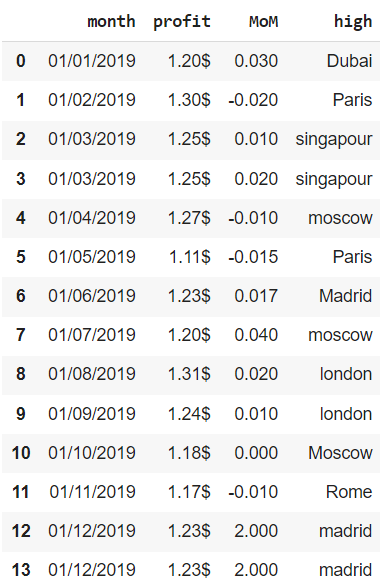
Воспользуемся методом .info() для получения общей информации о датасете.
|
1 |
financials.info() |
|
1 2 3 4 5 6 7 8 9 10 11 |
<class 'pandas.core.frame.DataFrame'> RangeIndex: 14 entries, 0 to 13 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 month 14 non-null object 1 profit 14 non-null object 2 MoM 14 non-null float64 3 high 14 non-null object dtypes: float64(1), object(3) memory usage: 576.0+ bytes |
Перейдем к поиску ошибок в данных.
Дубликаты
Поиск дубликатов
Заметим, что хотя данные представлены за 12 месяцев, в датафрейме тем не менее содержится 14 значений. Это заставляет задуматься о дубликатах (duplicates) или повторяющихся значениях. Воспользуемся методом .duplicated(). На выходе мы получим логический массив, в котором повторяющееся значение обозначено как True.
|
1 2 3 |
# keep = 'first' (параметр по умолчанию) # помечает как дубликат (True) ВТОРОЕ повторяющееся значение financials.duplicated(keep = 'first') |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
0 False 1 False 2 False 3 False 4 False 5 False 6 False 7 False 8 False 9 False 10 False 11 False 12 False 13 True dtype: bool |
|
1 2 |
# keep = 'last' соответственно считает дубликатом ПЕРВОЕ повторяющееся значение financials.duplicated(keep = 'last') |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
0 False 1 False 2 False 3 False 4 False 5 False 6 False 7 False 8 False 9 False 10 False 11 False 12 True 13 False dtype: bool |
Результат метода .duplicated() можно использовать как фильтр.
|
1 2 |
# с параметром keep = 'last' будет выведено наблюдение с индексом 12 financials[financials.duplicated(keep = 'last')] |

Также заметим, что если смотреть по месяцам, у нас две дублирующихся записи, а не одна. В частности, повторяется запись не только за декабрь, но и за март. Проверим это с помощью параметра subset.
|
1 2 |
# с помощью параметра subset мы ищем дубликаты по конкретным столбцам financials.duplicated(subset = ['month']) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
0 False 1 False 2 False 3 True 4 False 5 False 6 False 7 False 8 False 9 False 10 False 11 False 12 False 13 True dtype: bool |
|
1 2 |
# посчитаем количество дубликатов по столбцу month financials.duplicated(subset = ['month']).sum() |
|
1 |
2 |
Создадим новый фильтр и выведем дубликаты по месяцам.
|
1 2 3 |
# укажем параметр keep = 'last', больше доверяя, таким образом, # последнему записанному за конкретный месяц значению financials[financials.duplicated(subset = ['month'], keep = 'last')] |

Аналогичным образом мы можем посмотреть на неповторяющиеся значения.
|
1 |
( ~ financials.duplicated(subset = ['month'])).sum() |
|
1 |
12 |
Этот логический массив можно также использовать как фильтр.
|
1 |
financials[ ~ financials.duplicated(subset = ['month'], keep = 'last')] |
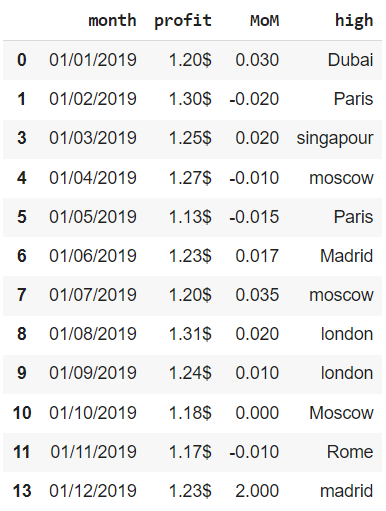
Обратите внимание, индекс остался прежним (из него просто выпали наблюдения 2 и 12). Мы исправим эту неточность при удалении дубликатов.
Удаление дубликатов
Метод .drop_duplicates() удаляет дубликаты из датафрейма и, по сути, принимает те же параметры, что и метод .duplicated().
|
1 2 3 4 5 6 |
# параметр ignore_index создает новый индекс financials.drop_duplicates(keep = 'last', subset = ['month'], ignore_index = True, inplace = True) financials |
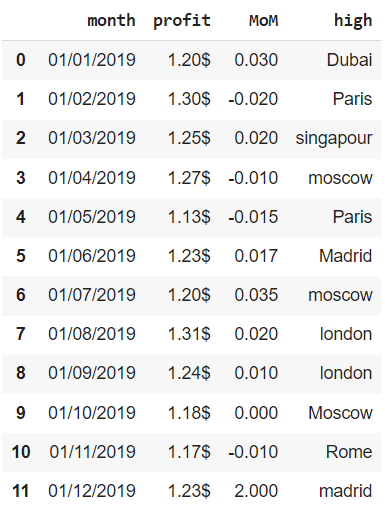
Неверные значения
Распространенным типом ошибок в данных являются неверные значения.
Базовый подход к поиску неверных значений — проверить, что данные не противоречат своей природе. Например, цена товара не может быть отрицательной.
В нашем случае мы видим, что в столбце MoM все строки отражают доли процента, а последняя строка — проценты. Из-за этого сильно искажается, например, средний показатель изменения выручки за год.
|
1 2 |
# рассчитаем среднемесячный рост financials.MoM.mean() |
|
1 |
0.17308333333333334 |
С учетом имеющихся данных вряд ли среднее изменение выручки (в месячном, а не годовом выражении) составило 17,3%. Заменим проценты на доли процента.
|
1 2 |
# заменим 2% на 0.02 financials.iloc[11, 2] = 0.02 |
Вновь рассчитаем средний показатель.
|
1 |
financials.MoM.mean() |
|
1 |
0.008083333333333335 |
Новое среднее значение 0,8% выглядит гораздо реалистичнее.
Форматирование значений
Тип str вместо float
Попробуем сложить данные о прибыли.
|
1 |
financials.profit.sum() |
|
1 |
'1.20$1.30$1.25$1.27$1.13$1.23$1.20$1.31$1.24$1.18$1.17$1.23$' |
Так как столбец profit содержит тип str, произошло объединение (concatenation) строк. Преобразуем данные о прибыли в тип float.
|
1 2 3 4 5 |
# вначале удалим знак доллара с помощью метода .strip() financials['profit'] = financials['profit'].str.strip('$') # затем воспользуемся знакомым нам методом .astype() financials['profit'] = financials['profit'].astype('float') |
Проверим полученный результат с помощью нового для нас ключевого слова assert (по-англ. «утверждать»).
Если условие идущее после assert возвращает True, программа продолжает исполняться. В противном случае Питон выдает AssertionError.
Приведем пример.
|
1 2 3 4 5 |
# напишем простейшую функцию деления одного числа на другое def division(a, b): # если делитель равен нулю, Питон выдаст ошибку (текст ошибки указывать не обязательно) assert b != 0 , 'На ноль делить нельзя' return round(a / b, 2) |
|
1 2 |
# попробуем разделить 5 на 0 division(5, 0) |

Выражение b != 0 превратилось в False и Питон выдал ошибку. Теперь вернемся к нашему коду.
|
1 2 |
# проверим превратился ли тип данных во float assert financials.profit.dtype == float |
Сообщения об ошибке не появилось, значит выражение верное (True). Теперь снова рассчитаем прибыль за год.
|
1 |
financials.profit.sum() |
|
1 |
14.709999999999999 |
Названия городов с заглавной буквы
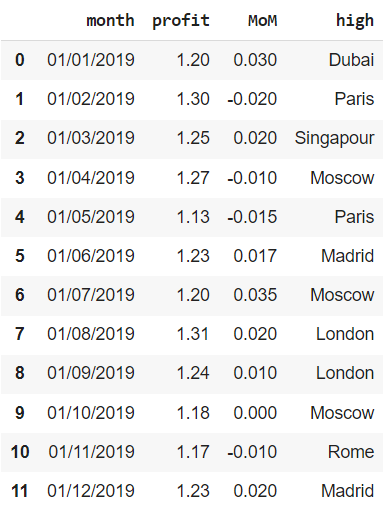
Остается сделать так, чтобы названия всех городов в столбце high начинались с заглавной буквы. Для этого подойдет метод .title().
|
1 2 |
financials['high'] = financials['high'].str.title() financials |
Дата и время
Как мы уже знаем, с датой и временем гораздо удобнее работать, когда они представляют собой объект datetime. В этом случае мы можем использовать все возможности Питона по анализу и прогнозированию временных рядов.
Начнем с того, что воспользуемся функцией pd.to_datetime(), которой передадим столбец month и формат, которого следует придерживаться при создании объекта datetime.
|
1 2 3 |
# запишем дату в формате datetime в столбец date1 financials['date1'] = pd.to_datetime(financials['month'], format = '%d/%m/%Y') financials |

Мы получили верный результат. Как и должно быть в Pandas на первом месте в столбце date1 стоит год, затем месяц и наконец день. Теперь давайте попросим Питон самостоятельно определить формат даты.
|
1 2 3 |
# для этого подойдет параметр infer_datetime_format = True financials['date2'] = pd.to_datetime(financials['month'], infer_datetime_format = True) financials |

У нас снова получилось создать объект datetime, однако возникла одна сложность. Функция pd.to_datetime() предположила, что в столбце month данные содержатся в американском формате (месяц/день/год), тогда как у нас они записаны в европейском (день/месяц/год). Из-за этого в столбце date2 мы получили первые 12 дней января, а не 12 месяцев 2019 года.
|
1 2 3 4 5 |
# исправить неточность с месяцем можно с помощью параметра dayfirst = True financials['date3'] = pd.to_datetime(financials['month'], infer_datetime_format = True, dayfirst = True) financials |

Теперь мы снова получили верный формат.
|
1 2 |
# убедимся, что столбцы с датами имеют тип данных datetime financials.dtypes |
|
1 2 3 4 5 6 7 8 |
month object profit float64 MoM float64 high object date1 datetime64[ns] date2 datetime64[ns] date3 datetime64[ns] dtype: object |
Удалим избыточные столбцы и сделаем дату индексом.
|
1 2 3 4 |
financials.set_index('date3', drop = True, inplace = True) # drop = True удаляет столбец date3 financials.drop(labels = ['month', 'date1', 'date2'], axis = 1, inplace = True) financials.index.rename('month', inplace = True) financials |
Посмотрим на еще один интересный инструмент. Предположим, что мы ошиблись с годом (вместо 2019 у нас на самом деле данные за 2020 год) или просто хотим создать индекс с датой с нуля. Для таких случаев подойдет функция pd.data_range().
|
1 2 3 4 5 6 7 8 |
# создадим последовательность из 12 месяцев, # передав начальный период (start), общее количество периодов (periods) # и день начала каждого периода (MS, т.е. month start) range = pd.date_range(start = '1/1/2020', periods = 12, freq = 'MS') # сделаем эту последовательность индексом датафрейма financials.index = range financials |
Как мы уже знаем, когда индекс имеет тип данных datetime, мы можем делать срезы по датам.
|
1 2 |
# напоминаю, что для datetime конечная дата входит в срез financials['2020-01': '2020-06'] |

Завершим раздел про дату и время построением двух подграфиков. Для этого вначале преобразуем индекс из объекта datetime обратно в строковый формат с помощью метода .strftime().
|
1 2 3 |
# будем выводить только месяцы (%B), так как все показатели у нас за 2020 год financials.index = financials.index.strftime('%B') financials |

Теперь используем метод .plot() библиотеки Pandas с параметром subplots = True.
|
1 2 3 4 5 6 7 8 9 |
# построим графики для размера прибыли и изменения выручки за месяц financials[['profit', 'MoM']].plot(subplots = True, # обозначим, что хотим несколько подграфиков layout = (1,2), # зададим сетку kind = 'bar', # укажем тип диаграммы rot = 65, # повернем деления шкалы оси x grid = True, # добавим сетку figsize = (16, 6), # укажем размер figure legend = False, # уберем легенду title = ['Profit 2020', 'MoM Revenue Change 2020']); # добавим заголовки |
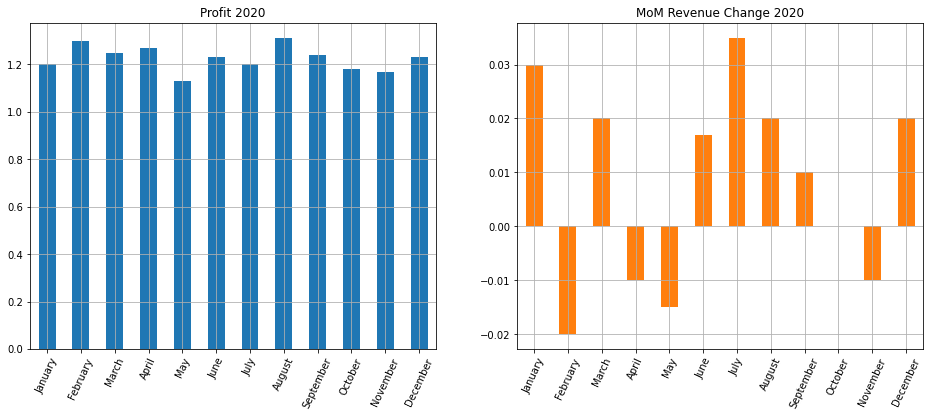
Подведем итог
Сегодня мы рассмотрели типичные ошибки в данных и способы их исправления. В частности, мы изучили как выявить и удалить дубликаты, обнаружить неверные значения и скорректировать неподходящий формат. Кроме того, мы еще раз обратились к объекту datetime и посмотрели на возможности изменения даты и времени.
Перейдем к работе с пропущенными значениями.